SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing
Author
- 저자:Taku Kudo, John Richardson (Google, Inc)
- EMNLP 2018
- Official Repo: https://github.com/google/sentencepiece
- Recommended Tutorial: https://github.com/google/sentencepiece/blob/master/python/sentencepiece_python_module_example.ipynb
Who is an Author?
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
장점
- 언어에 상관없이 적용 가능
- OOV 대처 가능
- 적은 vocab size로 높은 성능기록
- 빠름
Note
- dictionary 형태의 사전은 따로 프로퍼티로 선언되어있진 않음
- github issue 참고
Install
- python module 설치
- tf에서 사용가능한 모듈이 따로 있음 (computational graph안에 tokenizer 포함됨)
- 참고: https://github.com/google/sentencepiece/blob/master/tensorflow/README.md
1
2pip install sentencepiece
pip install tf_sentencepiece
- 참고: https://github.com/google/sentencepiece/blob/master/tensorflow/README.md
Usage
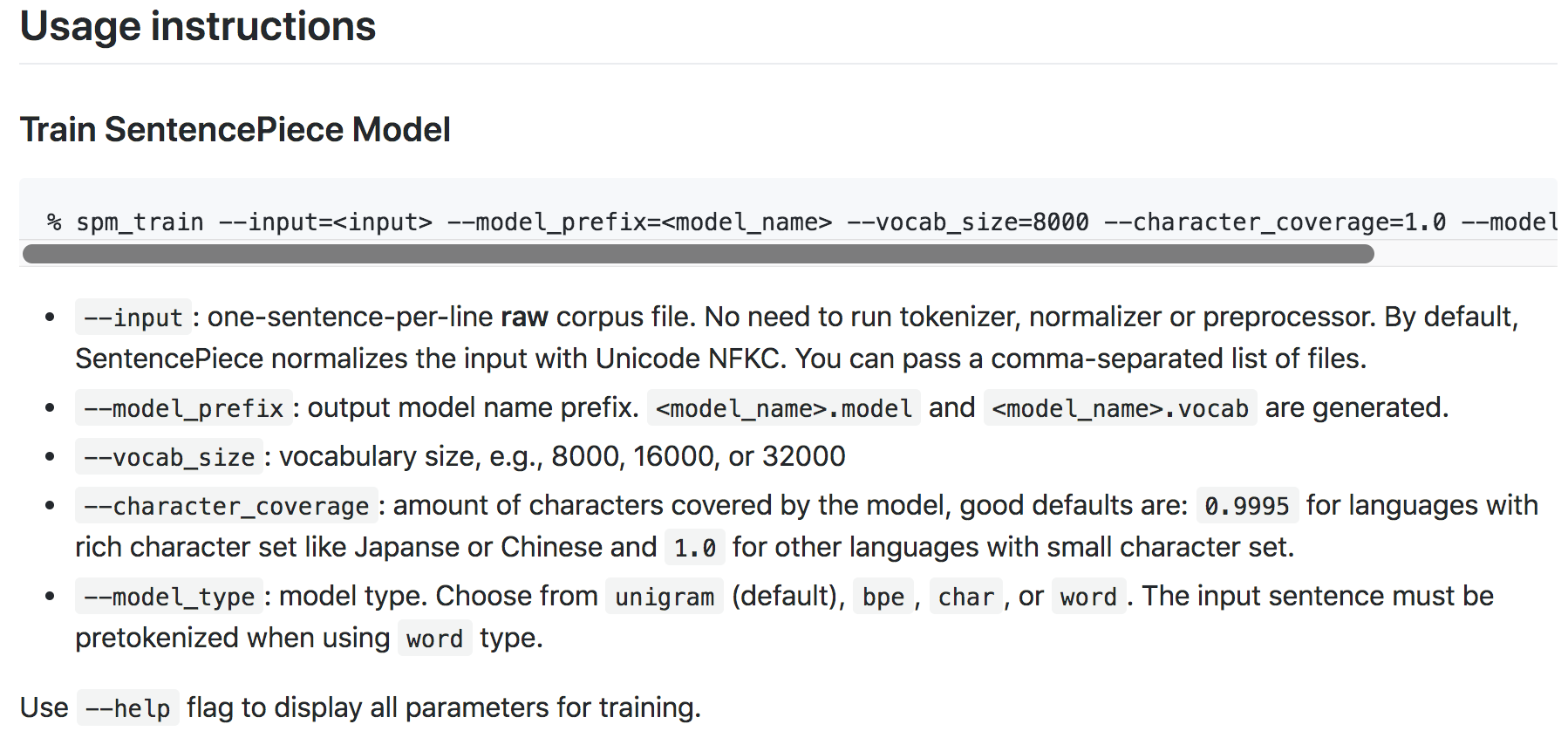
Training
- 전체적인 arg는 아래 그림 참조
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”} - input은 String이 아니라 문서 파일을 사용함
- vocab_size 때문에 에러가 날때가 있음, 실행할 때 에러메세지에서 적합한 vocab_size 알려주니 거기에 맞추면됨
- 아래와 같이 코드를 실행해주면 sentencepiece tokenizer가 학습이 됨
1 | import sentencepiece as spm |
SentencePiece에서는 Custom token을 2가지로 나누는데, Control symbol과 User defined symbols임
- Control symbol은
<s>, </s>와 같은 텍스트를 인코딩하고 디코딩할때 사용하는 특수 토큰임 - User defined symbol은 그냥 넣고 싶은거 넣는것임. 얘는 input text에 들어가면 나중에 extract할때 다른 것과 같이 하나의 piece로 인식됨
- 문서 참고
- Control symbol은
보통 Control symbol을 많이 쓰기 문에 추가해줘야함
control symbol인
[CLS], [SEP]토큰을 추가해주기 위해--control_symbols옵션을 사용함user defined symbol인
[MASK]토큰을 추가해주기 위해--user_defined_symbols옵션을 사용함default control token으로 pad, bos, eos, unk 토큰등이 있음
- pad 토큰의 경우 default 값은 비활성화라서 사전의 0번째 인덱스는 보통
<s>토큰임 - 우리는 pad 토큰도 쓸거기 때문에 활성화 시켜줘야하는데, 옵션값으로 id를 부여하면 활성화됨
--pad_id=0 --bos_id=1 --eos_id=2 --unk_id=3
- pad 토큰의 경우 default 값은 비활성화라서 사전의 0번째 인덱스는 보통
결과 화면
1 | sentencepiece_trainer.cc(116) LOG(INFO) Running command: --input=./data_in/sentencepiece_train.txt --model_prefix=m --vocab_size=778 --control_symbols=[CLS],[SEP] --user_defined_symbols=[MASK] --pad_id=0 --bos_id=1 --eos_id=2 --unk_id=3 |
Load model & Encoding, Decoding
학습 후 위키피디아 본문의 일부를 SentencePiece로 tokenization 해봄
default control symbol은 학습할때 넣어주었던 값대로 나옴
SentencePiece에서는 default control symbol을 인코딩시에 text 앞뒤에 추가할 수 있는 옵션이 있음
bos:eos옵션은 문장에<s> , </s>토큰을 추가함reverse옵션은 순서를 거꾸로 만들어서 인코딩함:표시로 중첩해서 사용할 수 있음- BERT에서는 굳이 쓸 필요 없고, 따로 추가하는 작업을 하는게 맞을 듯
1
2extra_options = 'bos:eos' #'reverse:bos:eos'
sp.SetEncodeExtraOptions(extra_options)SentencePiece tokenizer APIs (나머지는 문서 참조):
- raw_text-to-enc_text:
sp.EncodeAsPieces - raw_text-to-enc_id:
sp.EncodeAsIds - enc_text-to-raw_text:
sp.decode_pieces - enc_id-to-enc_text:
sp.IdToPiece
- raw_text-to-enc_text:
코드
1 | # Load model |
- 결과
1 | raw text: 초기 인공지능 연구에 대한 대표적인 정의는 다트머스 회의에서 존 매카시가 제안한 것으로 "기계를 인간 행동의 지식에서와 같이 행동하게 만드는 것"이다 |
전체 코드
1 | import sentencepiece as spm |
Note
- vocab_size 이슈를 해결하기 위해 hard_vocab_limit 옵션쪽을 확인해볼 것!
1
2templates = "--input={} --model_prefix={} --vocab_size={} --model_type={} --user_defined_symbols={} --hard_vocab_limit=false"
Reference
SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing