Improving Language Understanding by Generative Pre-Training (GPT)
Author
- 저자:Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever (Open AI,
Open AI다! 부럽(?)다)
Who is an Author?
Alec Radford라는 친군데, GPT논문 인용수가 젤 많겠지 했는데 오히려 Vision쪽에서 한 Generative model 인용수가 넘사임.. 원래 유명한 친구였음
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
느낀점
- 작은 변화가 큰 성능의 변화를 가져다줌
- Add auxiliary objective
- pre-training LM
Abstract
- NLU는 다양한 범위의 태스크를 가짐 ex) textual entailment, qa, semantic similarity assessment and document classification
- unlabeled data는 엄청 많고 labeled data는 매우 적음
- unlabeled data를 잘 쓰면 모델 성능에 도움줄 것임
- 우리는 generative pre-training of LM에 이를 적용했고 discriminative fine-tuning으로 성능을 높임
- 이전 방법과의 차이가 뭐냐면, 우리는 효과적인 fine-tuning을 위해 모델의 Architecture는 거의 안바꾸고 input을 바꾸는 방법을 썼음 (task-aware input transformation을 사용함)
- 우리가 제안하는 방법을 설명하기 위해 NLU의 다양한 태스크에 대한 benchmark를 보여줄 것임
- 우리의 general task-agnostic model이 특정 task에 특화되게 학습한 모델 보다 성능이 높았고 12개 Task 중에 9개에서 SOTA 찍었음
- 특히 commonsense reasoning(Stories Cloze Test) 은 8.9% 올랐고 qa(RACE)는 5.7%, text entailment(MultiNLI)는 1.5% 올랐음
1. Introduction
- raw text로부터 효과적으로 학습하는 능력은 supervised learning에 의존하는걸 완화시켜줄 수 있음
- supervised learning을 위해 일일이 손으로 labeling하는건 비용도 매우 비쌈
- supervision이 가능하다고쳐도, unsupervised 방식으로 good representation을 학습하는건 performace에 큰 boost를 줌
- 예를 들자면 word embedding 학습이 있음
- word-level information from unlabeled data 이상의 것을 얻어내는 건 두가지 이유 때문에 challenging함
- First, 어떤 타입의 optimization objectives이 차후 transfer learing을 위한 text representation을 배우는데 효과적인지 분명치 않음
- 최근 연구들은 LM, NMT, discourse coherence등 다양한 objectives들에 대해 적용되었음
- Second, 가장 효과적으로 학습된 representation을 target task에 대해서 transfer하는 방법에 대해서 합의 된게 없음(no consensus)
- 최근 연구들은 보통 task가 바뀜에 따라 model Architecture를 바꾸는 바꾸거나, learning objectives를 바꾸거나 하는 방법들을 썼었음
- First, 어떤 타입의 optimization objectives이 차후 transfer learing을 위한 text representation을 배우는데 효과적인지 분명치 않음
- 본 논문에서는 Language unserstanding task에 대해서 unsupervised pre-training and supervised fine-tuning을 결합한 semi-supervised approach방법을 제안함
- 본 연구팀의 목적은 다양한 task에 little adaptation이 가능한 universial representation을 학습하는 것임
- 처음엔 LM objective 쓸거고 그 다음엔 task에 맞는 supervised objective 쓸 것임
- Model backbone은 Trasnformer 쓸 것임
2. Related work
Semi-supervised learning for NLP
- 본 연구는 semi-supervised learning for NLP 범주에 속해 있음
- sequence labeling, text classification등에서 많이 쓰임
- 이전에는 unlabeled data로 word-level or phrase-level statistics를 계산해서 supervised model의 feature로 사용하는 방법이 있었음
- 몇년 전에는 word embedidngs 같은 것에 대한 연구도 많이 이뤄졌는데, 이건 word-level information에 대해 주로 다루지만 본 연구에서는 higher-level semantics에 대해서도 다루는 것을 목표로함
- 최근에는 unlabeled corpus로부터 Phrase-level, Sentence-level embeddings에 대한 연구도 많이 이뤄짐
Unsupervised pre-training
- Unsupervised pre-training은 semi-supervised learning의 speicial case인데, good initialzation point를 찾는 게 목적임
- 이전의 연구들은 image classificaiton, regression task 등에서 쓰였음
- 그 후의 연구들은 regularization scheme이나 better generalization을 위해서도 쓰였
- 최근 연구들은 뉴럴넷 학습을 돕기 위해서 쓰임 (image classificaiton, speech regcognition, entity disambiguation, and machine translation)
- 여기서 본 연구와 가장 가까운건 train을 돕는 것임; LM objective로 pre-training 후에 target task에 대해서 fine-tuning하는 것 with supervision
Auxiliary training objectives
- Auxiliary unsupervised training objectives를 추가하는 건 semi-supervised learning의 alternative 형태임
- 그 유명한 Collobert는 POS tagging, chunking, NER, LM등 다양한 auxiliary NLP Task를 사용해서 semantic role labeling의 성능을 올렸
- 본 연구에서도 auxiliary objective를 사용하지만 이미 unsupervised pre-training 단계에서 여러 언어적 특징들을 학습한걸 확인할 수 있었음
3. Framework
- 학습은 크게 두 단계로 나눔
- Pre-training stage: high-capacity language model을 학습
- Fine-tuning stage: labeled data를 통해 discriminative task에 대해서 학습
3.1 Unsupervised pre-training
- unsupervised corpus of token $U = {u_1, …, u_n}$에 대해서 standard LM objective를 최대로 하는 likelihood는 다음과 같음
- $${L_1(U) = \sum_i logP(u_i|u_{i-k}, …, u_{i-i} ; \Theta )}$$
- Model backbone: a multi-layer Transformer decoder (for LM)
$h_0 = UW_e+W_p$
$h_l = transformer_block(h_{l-1}) \forall i \in [1, n] $
$P(u) = softmax(h_nW_e^T)$
- Notations
- $k$ : size of the context window
- $P$ : $\Theta$ param을 갖는 neural net으로 모델링 된 조건부 확률; SGD로 학습됨
- $U = {u_{-k}, …, u_{-1}}$ : context vector of tokens
- $n$ : num of layers
- $W_e$ : token embedding matrix
- $W_p$ : position embedding matrix
3.2 Supervised fine-tuning
- Standard LM objective로 학습 후에 supervised target task에 대해서 fine-tuning 해야함
- final transformer block’s activation $h_l^m$을 $W_y$ param을 갖는 linear output layer에 한번 더 통과시켜서 $y$ 값을 예측함
- $${P(y|x^1, … , x^m) = softmax(h_l^mW_y)}$$
- 새로운 objective는 다음과 같음
- $${L_2(C) = \sum_{(x,y)}logP(y|x^1, … , x^m)}$$
- 여기에 auxiliary objective를 추가함
- fine-tuning할 때 generalization에 도움줌
- 학습할때 더 빠르게 수렴하게 해줌
- 최종 objective는 다음과 같음 (with weight $\lambda$)
- $L_3(C) = L_2(C) + \lambda * L_1(C)$
- Notations
- $C$ : a labeled dataset
- 최종적으로 fine-tuning때 추가되는 extra param은 $W_y$과 delimiter tokens을 위한 embeddings임
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
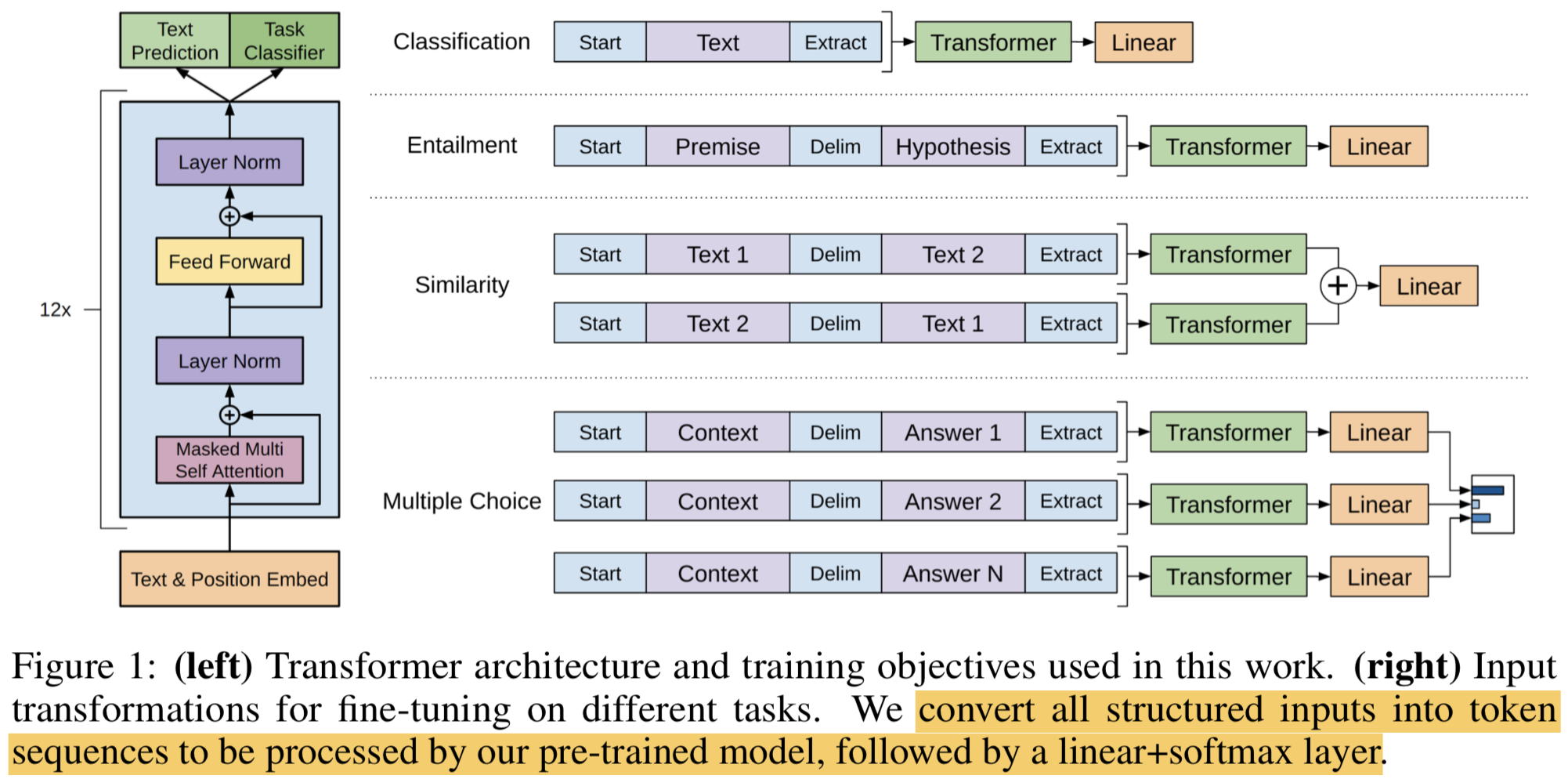
3.3 Task-specific input transformations
text classification 같은건 바로 fine-tune되지만, qa, text entailment 같은건 input format 바꿔줘야함 (input transformation)
모든 transformation에는 randomly initialized start and end token ($
,$)이 들어감 Textual Entailment:
- premise(전제) $p$와 hypothesis(가설) $h$ token sequence를 concat하는데 중간에 delimiter token ($)을 넣음
Similarity:
- 유사문장에는 순서가 의미가 없으므로 AB, BA 순서 모두 input으로 사용하고 중간에 delimiter 넣어줌.
- 그 후 각각 seq에서 $h_l^m$ 을 얻은 후 element-wise로 합치고 linear output layer에 feed 시킴
Question Answering and Commonsense Reasoning:
- document $z$, question $q$, set of possible answers {$a_k$}에 대해서 answer의 경우의 수에 맞게 3개를 delimiter 사용해서 concat함 [$z;q;$;a_k$]
- 각 seq에서 결과 값 구한 후 softmax layer에서 normalized해서 possible answer에 대한 output distribution을 구함
4 Experiments
4.1 Setup
Unsupervised pre-training
- Data:
- the BooksCorpus dataset for training LM
- contains over 7,000 unique unpublished books
- contains long stretches of contiguous text
- the 1B Word Benchmark (alternative dataset) for training LM, which used by a similar approach, ELMo
- shufffled at a sentence level
- destroying long-range structure
- the BooksCorpus dataset for training LM
Model specifications
- Model Backbone: 12-layer decoder-only transformer with masked self-attention heads
- 768 dimensional staets
- 12 attetnion heads
- position-wise feed-forward network
- 3072 dimensional inner states
- optim:
- Adam: lr=2.5e-4
- Warmup: 0~2000 step까지는 linear하게 lr을 증가 시키다가 다시 증가 된 값을 0으로 감소시킴 (cosine schedule 사용)
- epoch: 100
- minibatches: 64 randomly sampled
- token lenghth: contiguous sqeunces of 512 tokens
- Layernorm: $N(0,0.002)$
- token format: BPE
- dropout: 0.1 (embeddings, residual, attention)
- Modified version of L2 regularization: $w=0.01$
- Activation function: Gaussian Error Linear Unit (GELU)
- position embedding : use learnable embedding not sinusoidal version
Fine-tuning detials
- Add dropout to the classifier with a rate of 0.1
- Use Learning rate of 6.25e-5 and a batchsize of 32
- fine-tune speed: 3 epochs
- use linear learning rate decay schedule with warmup over 0.2% of training; $\lambda$ was set to 0.5
4.2 Supervised fine-tuning
- natural language inference, question answering, semantic similarity, and text classification 등의 Task에 대해서 해봄
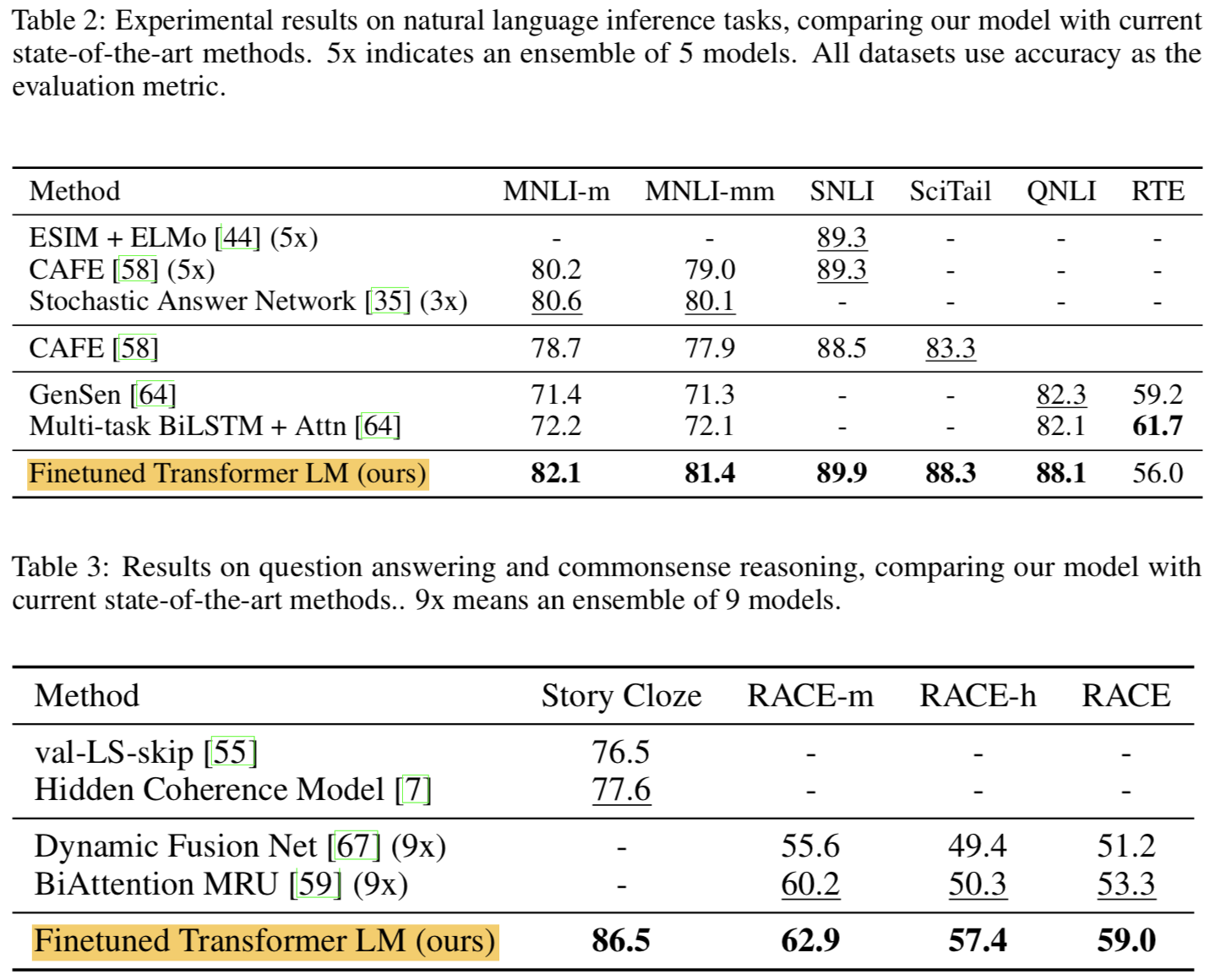
- Natural Language Inference
- Textual entailment라고도 알려짐
- 문장 pair를 읽어보고 그 둘의 관계가 (entailment / contradiction / neural) 인지 알아내는 것
- SNLI, MNLI, QNLI, SciTail, RTE 등 여러 데이터셋에서 평가
- SOTA도 이겼음
- Question answering and commonsense reasoning
- RACE, Story Cloze 등 여러 데이터셋에서 평가
- Natural Language Inference
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
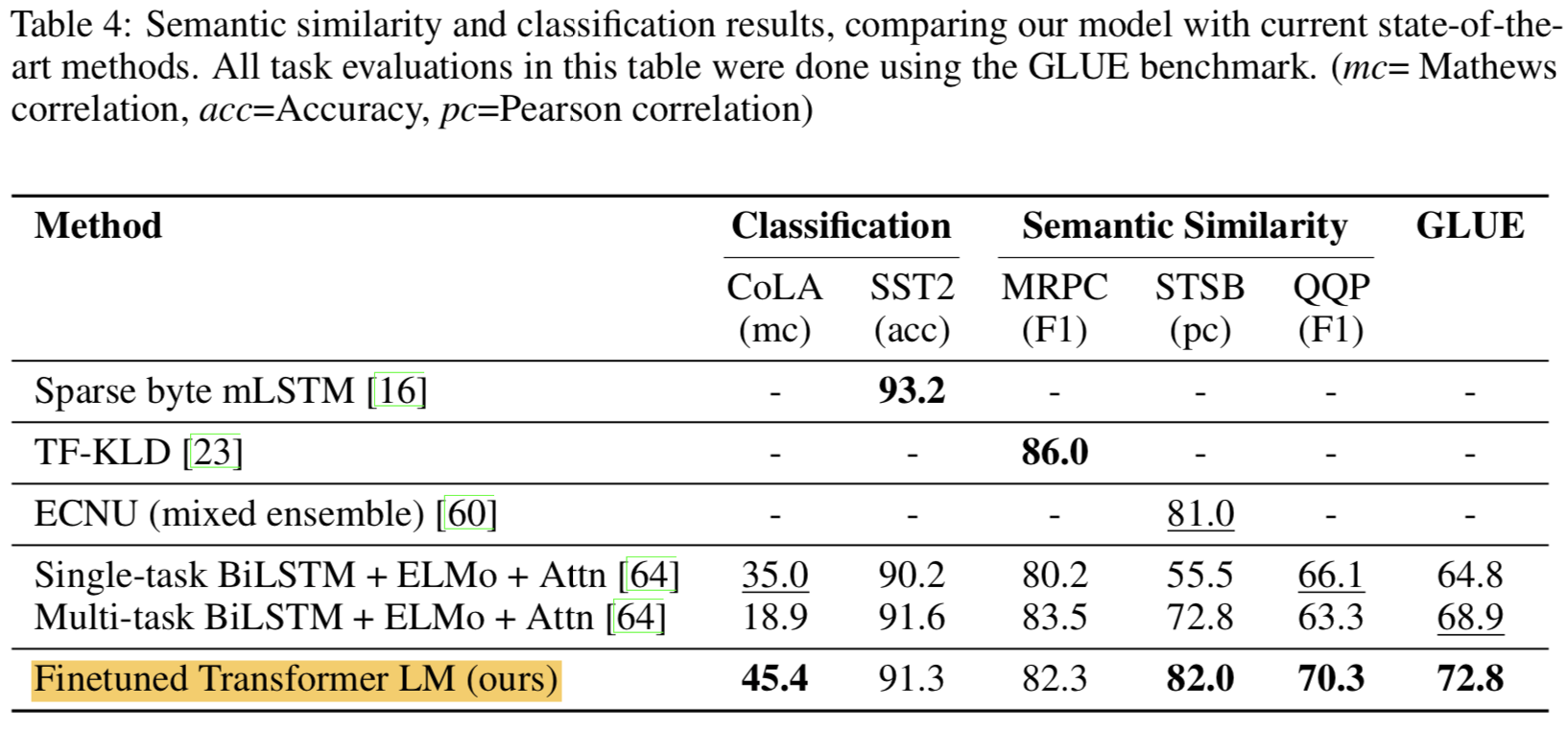
- Semantic Similarity
- Recognizing rephrasing of concepts, understanding negation and handling syntactic ambiguity
- MRPC, QQP, STS-B 등의 데이터 셋에서 평가
- classification
- CoLa (Corpus of Linguistic Acceptability): 문법적으로 맞는지 판단
- SST-2: 감성분석
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
- 결과적으로 12개 데이터셋 중에서 9개가 SOTA 찍음
5. Analysis
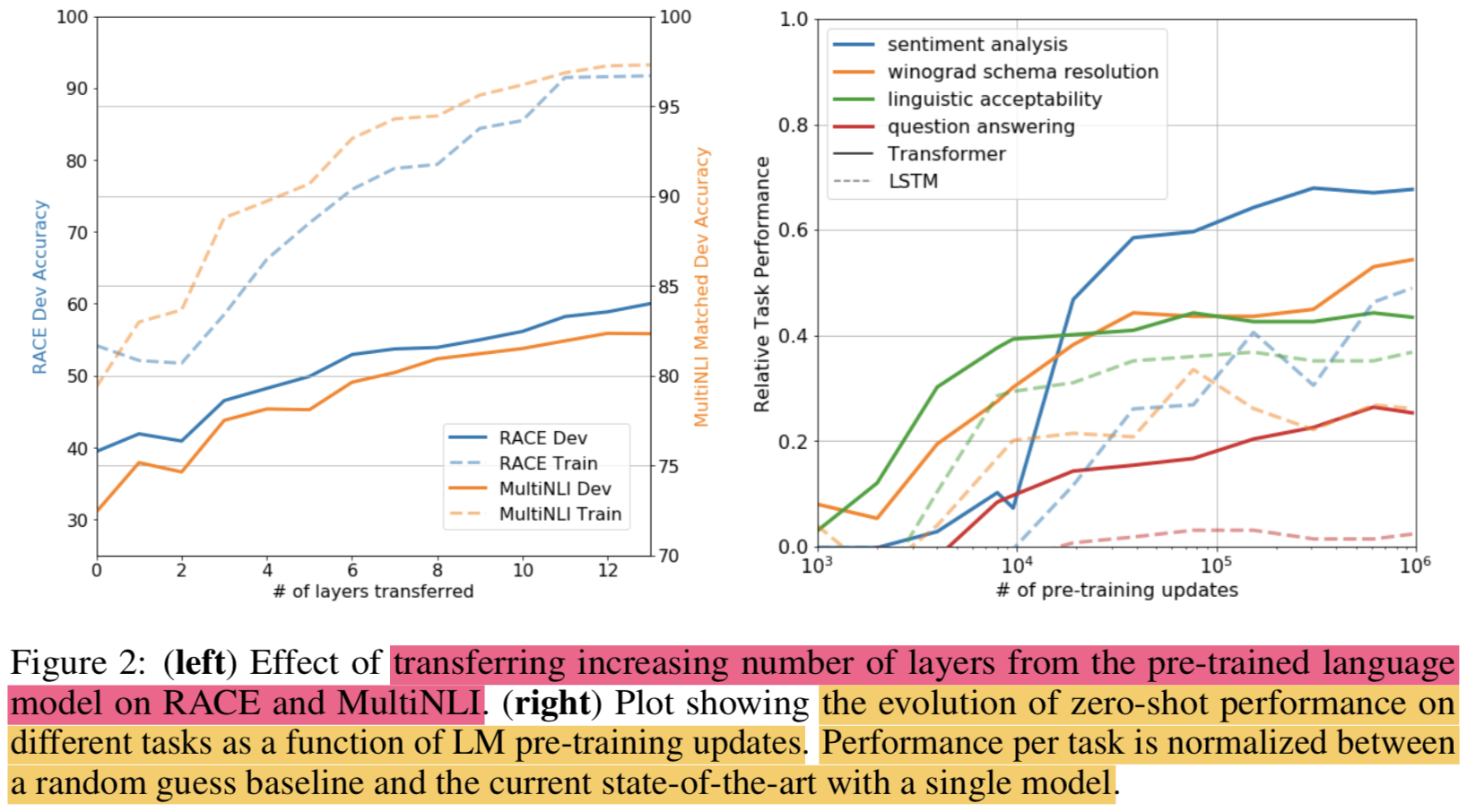
Impact of number of layers transferred
- 여러개의 layer를 transfer learning 할 때 효과에 대해서 관찰해봄
- the standard result that transferring embeddings improves performance and that each transformer layer provides further benefits up to 9% for full transfer on MultiNLI.
- This indicates that each layer in the pre-trained model contains useful functionality for solving target tasks.
Zero-shot Behaviors
- LM pre-training이 왜 효과적인지 알아보고자함
- 일단 transformer가 다른 애들보다 더 LM을 잘 학습하고 있음
- the performance of these heuristics is stable and steadily increases over training suggesting that generative pretraining supports the learning of a wide variety of task relevant functionality
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
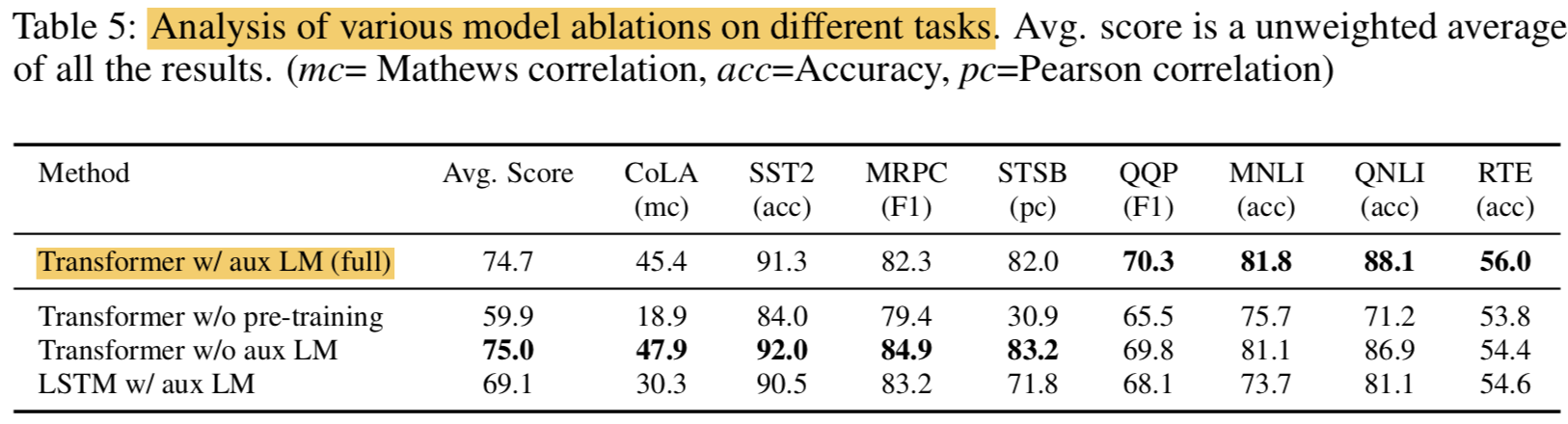
Ablation studies
- w/o pre-training: 성능이 14.8%까지 떨어짐.. ptre-training 매우 중요함
- w/o aux LM: pre-training은 했지만 fine-tune할때 LM빼면 데이터 적은 경우에 대해서는 성능 오히려 더 잘나왔지만 데이터 많은 경우에 대해서는 확실히 성능이 좀 떨어짐 (그렇게 큰 차이는 없긴했음)
- LSTM w/ aux LM: 딴건 다 똑같고 model backbone을 transformer에서 LSTM으로 바꿔쓴ㄴ데 성능이 전체적으로 떨어짐(MRPC만 더 높음)
- 결론: pre-training도 aux objective(보조적인 목표함수)도 중요하다
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
6. Conclusion
- generative pre-training + discriminative fine-tuning의 힘은 강력했음
- 12개 dataset 중 9개에서 SOTA 찍었음
- 본 논문의 연구가 unsupervised learning에 대한 새로운 연구에 도움이 되길 바람(실제로 매우 그렇게 됨)
Reference
Improving Language Understanding by Generative Pre-Training (GPT)