Document Expansion by Query Prediction
Author
- 저자:
- Rodrigo Nogueira, Wei Yang, Jimmy Lin, and Kyunghyun Cho
(New York University, Facebook AI Research), 2019
- Rodrigo Nogueira, Wei Yang, Jimmy Lin, and Kyunghyun Cho
- 조경현 교수님과 co-work
- 같은 년도에 쓴 Passage Re-ranking with BERT도 인용수가 높은 편 (4페이지 짜리인데도)
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
느낀점
- 요즘엔 T5로 시도한 방법들이 결과가 좋다고 나오고 있음
- DE (document expansion) 관련 논문들이 은근히 없다.. 다 QE (Query expansion)
- BERT를 검색에 적용한 논문들은 거의 re rank 수준.. inverted index에 적용한건 거의 없고 약간 흑마법처럼 보이기도..
- 참고
Abstract
- 검색을 효과적으로 개선하는 방법중 하나는 문서 텀을 확장하는 것임
- QA 시스템의 관점에서는 문서가 질문을 잠재적으로 포함한다고도 볼 수 있음
- (query, relevant documents) pair 셋으로 seq2seq 모델 학습해서 query 예측하는 방법 제안
- re-ranking component와 결합하면 two retrieval task에서 SOTA 결과 나옴
Introduction
- query term과 relevant doc 간의 “vocabulary mismatch” problem는 IR에서 메인 challenge중 하나임
- neural retrieval models이 등장함에 따라 이 문제는 대부분 query expansion 기술쪽으로 적용됨
- 개선된 랭킹을 위해 semantic level에서 문서와 매칭을 시도했지만 대부분 규모가 큰 검색엔진에서는 initial retreival 단계에서 exact term match를 사용함
- query representation은 풍부해지기 시작했지만 document representation은 그에 비해 변화가 크게 없었음
- 본 논문에서는 document representation을 개선하는 방법쪽으로 접근함
This is the first successful application of document expansion using neural networks that we are aware of- MS MARCO dataset에서 best result 기록
- DE의 장점: indexing 가능
- 눈에 띌만한 개선효과 거둠
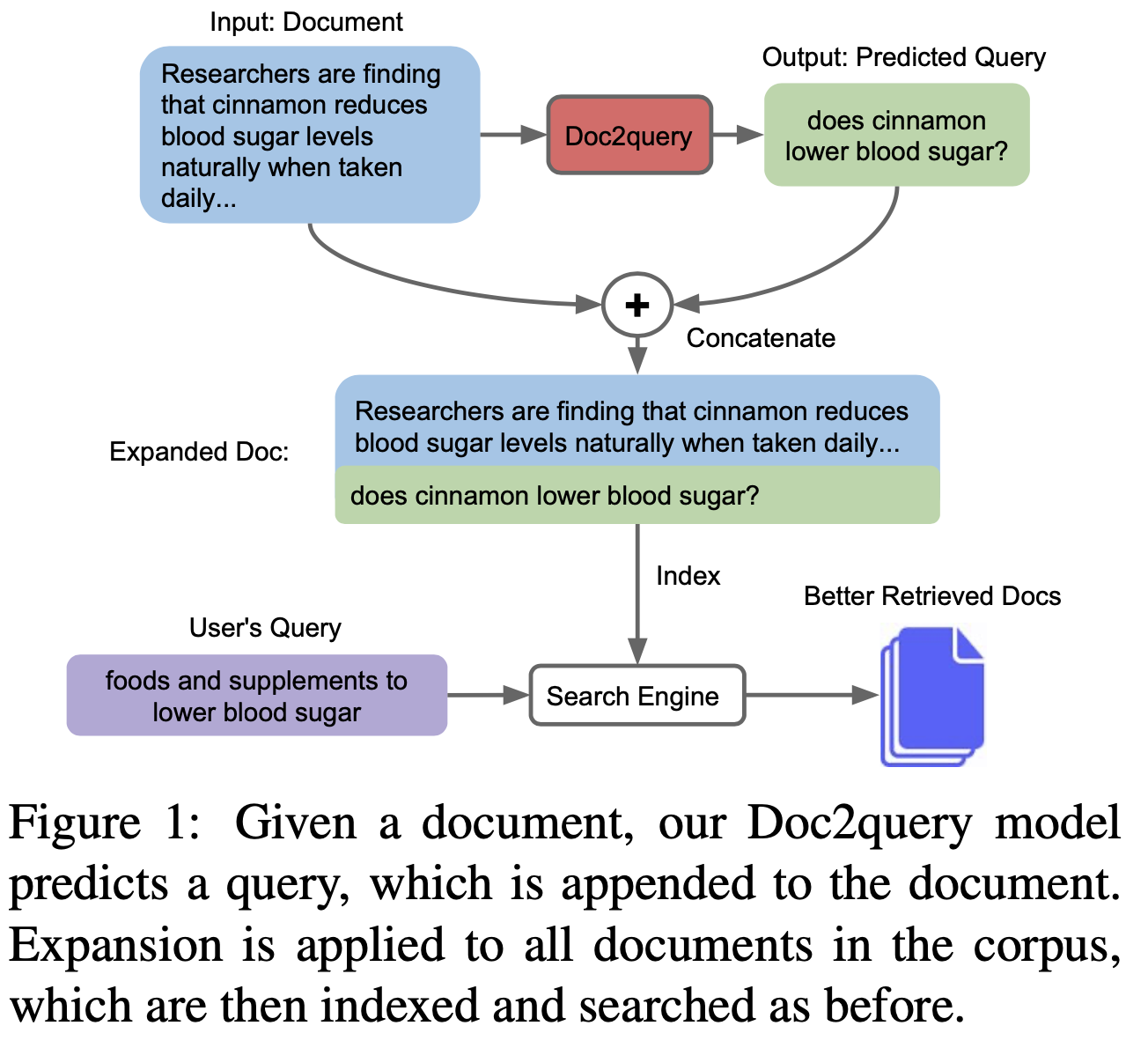
Method: Doc2query
- 제안 방법은
"Doc2query"라 칭함 - seq-to-seq transformer model로 (query, relevant document) 학습 & 생성
- Moses tokenizer로 한번 짜른 뒤 BPE로 토크나이징함 (생성되는게 BPE면 어떡하나?)
- document는 앞에서 400 토큰까지 사용하고 query는 100 토큰까지 사용
- top-k random sampling 을 통해 10개의 질의를 예측함
- 확장된 문서가 인덱싱 되고 나면 BM25를 통해 결과 출력함
- BERT 이용해서 re-rank 함 (option)
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
Experimental Setup
모델 학습과 평가를 위해 두가지 데이터셋 활용
- MS MARCO: a passage re-ranking dataset with 8.8M passages obtained from the top-10 results retrieved by the
Bing search engine (from 1M queries).- tr: 500k pairs (query, relevant document)
- 질의는 평균적으로 한개정도의 relevant passage를 가짐
- dev & test: 6,900 queries (dev set은 doc 포함)
- tr: 500k pairs (query, relevant document)
- TREC-CAR: the input query is the concatenation of a Wikipedia article title with the title of one of its sections. The ground-truth documents are the paragraphs within that section. 데이터셋은 크게 5개의 predefined fold로 구성됨
- tr: 앞의 4개 fold (3M queries)
- val: 1개 fold (700k queries)
- test: 2,250 quries
평가 모델
- BM25
- BM25 + Doc2query
- RM3 (query expansion)
- BM25 + BERT
- BM25 + Doc2query + BERT
Results
- BM25가 베이스라인임
- 예시 문장은 아래와 같음 (이정도로 잘되진 않을 것 같은데, 문서 도메인이 중요할 듯)
- input document에서 몇 단어를 copy하는 경향 있음
term re-weighting에 효과적일 수 있다(중요한 단어를 재생산하는 것이니?!) ->약간 귀에걸면 귀걸이 코에걸면 코걸이 같기도..- 문서에 없던 단어도 생성하기도함
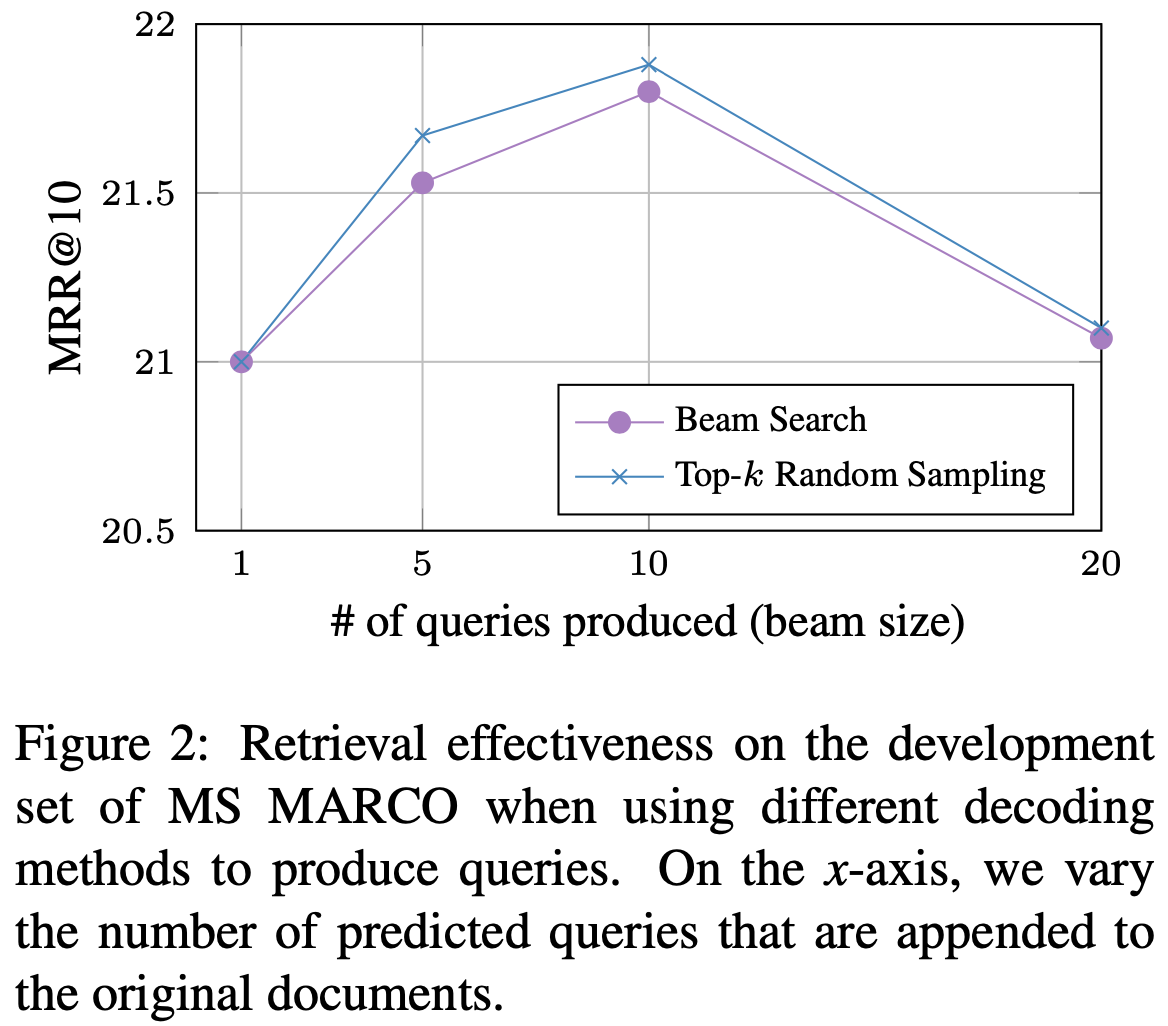
비율은 대략 69:31 = 기존단어:새단어- 대략 10개 query로
top-k random sampling > beam search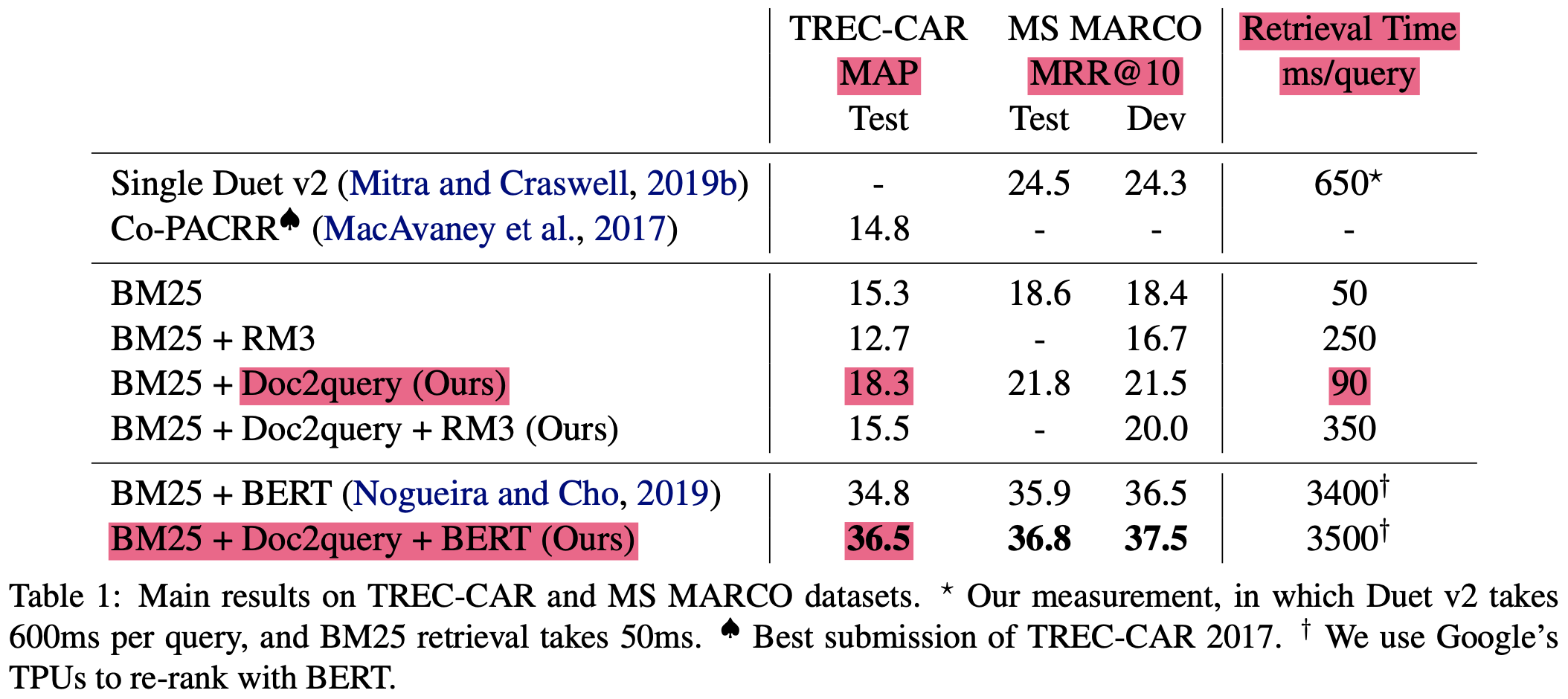 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
Conclusion
- neural net 기반 document expasnion의 성공적인 첫 사례다!
- rich input signal이 있는 longer document의 경우 neural models은 document expansion에 매우 유용하다
- runtime이 아닌 indexing time에 자원을 투자할 수 있음
- OpneNMT, Anserini(BM25), TensorFlow BERT 써서 구현함
Document Expansion by Query Prediction
https://eagle705.github.io/2020-10-22-DocumentExpansionByQueryPrediction/