LLM(Large-Scale Language Model)을 위한 넓고 얕은 지식들
최근 LLM 관련 일을 하면서 익혀야할게 너무나 많다는 사실을 새삼스럽게 알게 되었다. 예전엔 아 그냥 하면 되지~ 정도로 생각했는데.. 디테일한게 생각보다 많구나 싶어서 이것 저것 많이 보기야 봤는데 머리에 남는게 없는 것 같아서 글로 간단하게 그리고 약간 어쩔수 없이 파편화된 상태로 정리해놓으려한다. 나 포함 누군가에게 도움이 되기를 바라며
PyTorch로 분산 어플리케이션 개발하기
- 제일 먼저 볼 것!
- 참고
- Pytorch Multi-GPU 정리 중
- 분산학습을 할때 로그를 찍으면 프로세스 개수만큼 찍힌다 -> 따로 처리가 필요해짐!
if rank==0일때만 찍게 한다던지
code snippet
all-reduce
- EleutherAI gpt-neox
1
2
3
4
5
6def reduce_losses(losses):
"""Reduce a tensor of losses across all GPUs."""
reduced_losses = torch.cat([loss.clone().detach().view(1) for loss in losses])
torch.distributed.all_reduce(reduced_losses)
reduced_losses = reduced_losses / torch.distributed.get_world_size()
return reduced_losses
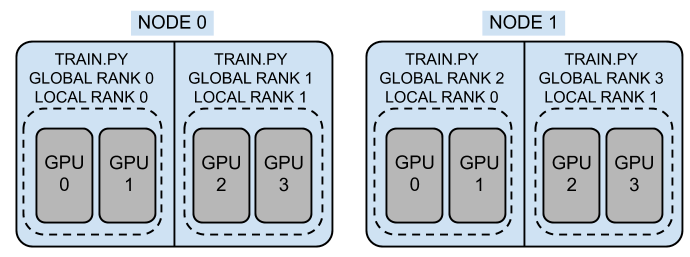
Multi GPU & Node
모델을 학습하다보면 결국 multi-gpu, multi-node등으로 스케일을 키울 수 밖에 없다
multi-gpu는 주로 Data Parallel(DP)할때 많이 쓴다 (스레드 기반이라고)
multi-node는 여러 노드에서 multi-gpu를 쓰며 DP를 하는데 Distributed Data Parallel(DDP)라 부른다 (프로세스 기반이라고)
최근엔
torch.distributed.run(launch)을torchrun이 대체했다- torchrun은 pytorch 1.1x이상부터 쓸 수 있다
torchrun을 사용해도 init process 과정을 아래처럼 거쳐야하는데 huggingface에서는 TrainingArguments쪽에 해당 부분이 내장되어있다. huggingface를 쓸땐 중복 선언하지 않게 조심!
1
2
3
4
5
6
7import torch.distributed as dist
dist.init_process_group(backend="gloo|nccl")
local_rank = int(os.environ["LOCAL_RANK"])
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[local_rank],
output_device=local_rank)multi-node를 쓸 경우 네트워크등 모종의 이유로 iteration당 시간은 조금 더 늘어날 수 있다 (하지만 더 많은 데이터를 본다!)
HPC
- reference: https://docs.likejazz.com/wiki/HPC/
- DeepOps
SLURM
slurm에는 많은 옵션들이 존재하는데, 이 옵션에 대해서 몇가지만 정리해보고자한다.
- SLURM에 대한 전반적인 가이드 자료
ex) sbatch script 예시1
2
3
4
5
6
7
8
9
10
11
12#!/bin/bash
#SBATCH --nodes=1
#SBATCH --gpus-per-node=8
#SBATCH --cpus-per-task=16
#SBATCH --ntasks-per-node=1
#SBATCH --partition=batch
#SBATCH --output=logs/%j.%x.info.log
#SBATCH --error=logs/%j.%x.error.log
#SBATCH --exclude=제외할노드주소
export MASTER_ADDR=$(hostname -i | cut -d' ' -f1)
export WORLD_SIZE=$((SLURM_JOB_NUM_NODES * SLURM_NTASKS_PER_NODE)) ntasks-per-node- 각 노드에서 살행되는 프로세스 수인듯
#SBATCH --gres=gpu:1와#SBATCH --gpus-per-task=1의 차이- pyxis로 enroort로 만든 sqsh 이미지 실행방법
1 | srun -l \ |
- drain 노드 확인
1 | # 상태조회 |
- 전체 노드 스펙 확인
- cpu, gpu, socket 개수, 메모리등 확인가능
cat /etc/slurm/slurm.conf
- 각 노드 스펙 확인
cat /etc/nhc/nhc.conf
- job 히스토리 확인
sacct
- 사용자 조회, 그룹 조회
sacctmgr list user,sacctmgr show account
- drain 이벤트 조회
sacctmgr list event
Pyxis
- Slurm Workload Manager를 위한 SPANK(Slurm Plug-in Architecture for Node and job (K)control) 플러그인임
- srun 명령어로 containerized task를 클러스터에서 돌릴 수 있게 해줌!
- 이미지 배포에 오랜 시간이 걸리는데, 각 노드에
$ enroot list로 이미지가 존재하면 container-name 지정으로 호출할 수 있다. 이 경우 이미지 전송을 하지 않으므로 매우 빠르게 실행 가능함. - 예시
$ srun --gres=gpu:1 -N2 -l --container-name=pytorch-slurm nvidia-smi
Enroot PyTorch hook
srun은SLURM_으로 시작하는 다양한 환경변수를 셋팅해준다. 하지만RANK,WORLD_SIZE는torchrun이 셋팅함- enroot의
hooks/extra에50-slurm-pytorch라는 hook2이 있어서, 만약 PyTorch 이미지인 경우PYTORCH_VERSION환경변수가 있는지 확인하고,SLURM_*을 이용해torchrun이 해주는RANK, WORLD_SIZE, MASTER_ADDR등을 대신 설정해준다. - 따라서 pyxis로 enroot 이미지를 srun 할 경우 따로 torchrun 할 필요 없으며, rank/size를 얻기 위한 MPI 통신도 필요없다.
이 부분은 잘 이해가 안간다..!
분산 GPU 학습가이드
- Azure 가이드를 참고한다
- MPI(메시지 전달 인터페이스)
- Horovod
- DeepSpeed
- Open MPI의 환경 변수
- PyTorch
- InfiniBand를 통해 GPU 학습 가속화
MPI
- 각 노드에 지정된 수의 프로세스를 시작하는 MPI 작업을 지정해야함
- 노드별로 1개씩 프로세스를 실행할 수도 있고 디바이스/GPU 수만큼 프로세스를 시작할 수도 있음
- 참고
- OMPI_COMM_WORLD_RANK - 프로세스의 순위
- OMPI_COMM_WORLD_SIZE - 세계 크기 (전체 프로세스 개수)
- AZ_BATCH_MASTER_NODE - MASTER_ADDR:MASTER_PORT 포트가 있는 기본 주소
- OMPI_COMM_WORLD_LOCAL_RANK - 노드에 있는 프로세스의 로컬 순위
- OMPI_COMM_WORLD_LOCAL_SIZE - 노드의 프로세스 수
PyTorch
- PyTorch의 네이티브 분산 학습 기능(torch.distributed -> torchrun) 사용하기
- 프로세스 그룹 초기화
- torch.distributed.init_process_group(backend=’nccl’, init_method=’env://‘, …)
- 프로세스를 그룹핑해야함
- 프로세스 그룹이 모든 분산 프로세스에서
torch.distributed.init_process_group를 호출해서 만들어짐 - init_method는 각 프로세스가 서로를 검색하는 방법, 통신 백 엔드를 사용하여 프로세스 그룹을 초기화하고 확인하는 방법을 알려줌. 기본적으로 init_method가 지정되어 있지 않으면 PyTorch에서는 환경 변수 초기화 메서드(env://)를 사용
- 이를 위해 다음의 환경변수를 셋팅해놔야함
- MASTER_ADDR - 0 순위의 프로세스를 호스팅할 컴퓨터의 IP 주소입니다.
- MASTER_PORT - 0 순위의 프로세스를 호스팅할 컴퓨터의 사용 가능한 포트입니다.
- WORLD_SIZE - 총 프로세스 수입니다. 분산 학습에 사용되는 디바이스의 총수(GPU)와 같아야 합니다.
- RANK - 현재 프로세스의 (전체) 순위입니다. 가능한 값은 0~(세계 크기 - 1)입니다.
- LOCAL_RANK - 노드 내 프로세스의 로컬(상대) 순위입니다. 가능한 값은 0~(노드의 프로세스 수 - 1)입니다. 이 정보는 데이터 준비와 같은 많은 작업이 노드별로 한 번만 수행되어야 하기 때문에 유용합니다(일반적으로 local_rank = 0 ->>>>> 노드별로 한개의 프로세스만 띄운다는 뜻일까?)
- NODE_RANK - 다중 노드 학습을 위한 노드의 순위입니다. 가능한 값은 0~(총 노드 수 - 1)입니다.
- 프로세스 그룹이 모든 분산 프로세스에서
- 프로세스 그룹 초기화
- 시작 옵션
- 프로세스별 시작 관리자: 시스템은 프로세스 그룹을 설정하기 위한 관련 정보(예: 환경 변수)를 모두 사용하여 모든 분산 프로세스를 시작합니다.
- 노드별 시작 관리자: 각 노드에서 실행될 유틸리티 시작 관리자를 클러스터에 제공합니다. 유틸리티 시작 관리자가 지정된 노드에서 각 프로세스의 시작을 처리합니다. 각 노드 내에서 로컬로 RANK 및 LOCAL_RANK가 관리자에 의해 설정됩니다. torch.distributed.launch 유틸리티(아마 torchrun도!)와 PyTorch Lightning은 모두 이 범주에 속합니다.
- 예시
1
2
3
4python -m torch.distributed.launch --nproc_per_node <num processes per node> \
--nnodes <num nodes> --node_rank $NODE_RANK --master_addr $MASTER_ADDR \
--master_port $MASTER_PORT --use_env \
<your training script> <your script arguments> - HuggingFace를 사용할 경우
- Hugging Face는 torch.distributed.launch와 함께 변환기 라이브러리를 사용하여 분산 학습을 실행하기 위한 예제를 다수 제공
- Trainer API를 사용하여 이러한 예제와 사용자 지정 학습 스크립트를 실행하려면 torch.distributed.launch 사용 섹션을 따름
- 프로세스별 시작 옵션을 이용해 torch.distributed.launch를 사용하지 않고도 분산 학습을 실행할 수 있습니다. 이 방법을 사용하는 경우 유의해야 할 한 가지 사항은 변환기
TrainingArguments에서 로컬 순위가 인수(--local_rank)로 전달될 것으로 예상한다는 점입니다. torch.distributed.launch에서는 –use_env=False일 때 이 작업을 처리하지만, 프로세스별 시작을 사용하는 경우 Azure ML에서 LOCAL_RANK 환경 변수만 설정하므로 –local_rank=$LOCAL_RANK 학습 스크립트에 대한 인수로 로컬 순위를 명시적으로 전달해야함- local_rank (int, optional, defaults to -1) — Rank of the process during distributed training.
- torchrun등을 안쓰고도 trainer API의 인자로 들어가는 TrainingArguments에 local_rank를 넣어줘서 돌릴 수 있다는거 같은데 확인을 해봐야할듯
- 예시
InfiniBand를 통해 분산된 GPU 학습 가속화
- 모델을 학습하는 VM 수가 늘어남에 따라 모델 학습에 필요한 시간이 줄어듬. 시간 감소는 학습 VM 수에 따라 선형적으로 비례함. 예를 들어 1개의 VM에서 모델을 학습하는 데 100초가 걸릴 경우 2개의 VM으로 동일한 모델을 학습하면 이상적으로 50초가 걸림. 4개의 VM에서 모델을 학습하려면 25초가 걸림.
- InfiniBand는 이러한 선형적 확장을 유지하는 데 있어서 중요한 요소
- InfiniBand는 클러스터에서 노드 간에 지연 시간이 낮은 GPU 간 통신을 가능하게 해줌. InfiniBand를 사용하려면 특별한 하드웨어가 필요함
- 이러한 VM은 대기 시간이 짧은 고대역폭 InfiniBand 네트워크를 통해 통신하는데, 이는 이더넷 기반 연결보다 훨씬 더 성능이 뛰어남!!
LM
whole word masking
- huggingface에서는 PLM을 위한 많은 함수들을 제공하고 있다
- wordpiece, bbpe, cbpe를 테스트한 이후에는 whole word masking등에 관심을 기울이게 되는데 이미 구현해놨으니 참고해보면 좋을 듯하다
- DataCollatorForWholeWordMask
- 사용법은 해당 모듈을 github에 검색해보면 대략 나온다
LLM(Large-Scale Language Model)을 위한 넓고 얕은 지식들