Elastic Search 정리
아파치 루씬 기반의 Java 오픈소스 분산 검색엔진임
ES를 통해 루씬 라이브러리를 단독으로 사용할 수 있게됨
- 많은 양의 데이터를 빠르게, 거의 실시간(NRT, Near Real Time)으로 저장, 검색, 분석할 수 있음
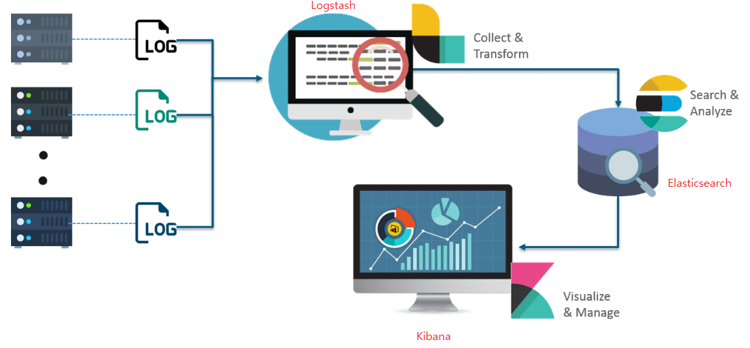
ELK 스택이란 다음과 같음
- Logstash
- 다양한 소스(DB, csv, …)의 로그 또는 트랸쟉션 데이터를 수집, 집계, 파싱하여 ES로 전달
- Elasticsearch
- Logstash 로 전달 받은 데이터를 검색 및 집계해서 필요한 관심 정보를 획득
http://localhost:9200/
- Kibana
- ES의 빠른 검색을 통해 데이터를 시각화 및 모니터링함
- 키바나는 JVM에서 실행되는 엘라스틱서치와 로그스태시와 달리 node.js로 실행하는 웹애플리케이션임
http://localhost:5601/
- Logstash
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
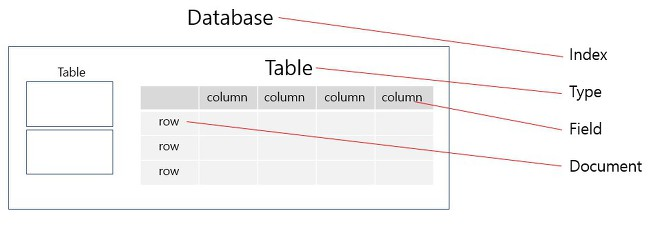
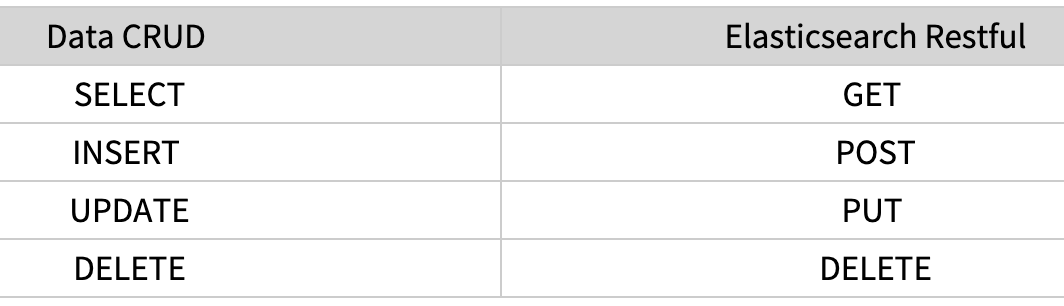
RDB와 Es 비교
- Database -> Index
- Table -> Type
- column -> Field
- row -> Document
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}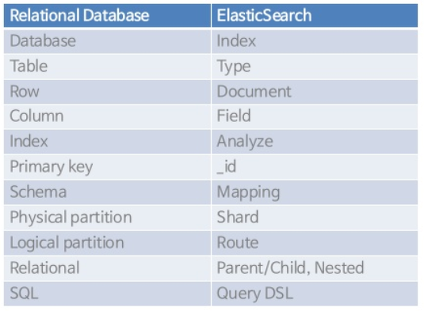 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
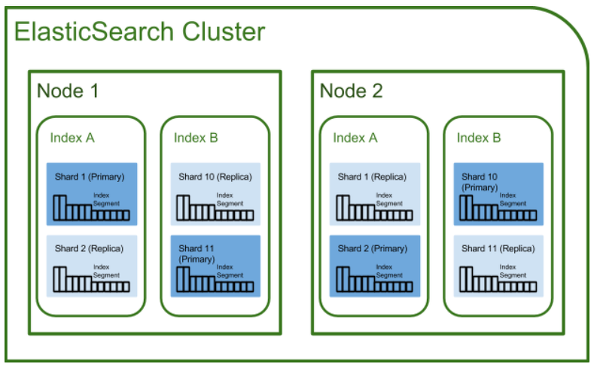
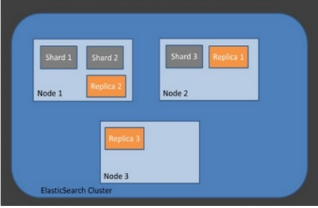
ES 아키텍쳐 / 용어 정리
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}- 클러스터
- 노드들의 집합
- 서로 다른 클러스터는 데이터의 접근, 교환이 불가
- 노드
- ES를 구성하는 하나이 단위 프로세스임
- 역할에 따라 Master-eligible, Data, Ingest, Tribe 등으로 구분 가능
- Master-eligible: 클러스터 제어하는 마스터 노드 (인덱스 생상, 삭제 / 클러스터 노드 추적, 관리 / 데이터 입력시 어느 샤드에 할당할지 결정)
- Data node: CRUD 작업과 관련있는 노드 (CPU, 메모리를 많이 써서 모니터링 필요함, Master node와 분리되는 것이 좋음)
- Ingest node: 데이터 변환, 사전 처리 파이프라인
- Coordination only node: 로드밸런서와 비슷한 역할
- 인덱스 (index), 샤드 (Shard), 복제 (Replica)
- 인덱스: RDB의 DB와 대응됨
- 샤드: 데이터 분산해서 저장하는 방법임. scale out을 위해 index를 여러 shard로 쪼갬. 기본적으로는 1개 존재하고 나중에 개수 조정가능
- 복제: 또 다른 형태의 shard라 할 수 있음. 노드를 손실했을 경우 데이터 신뢰성을 위해 샤드들 복제하는 것. 그러므로 replica는 서로 다른 노드에 존재하는 것이 좋음
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
- 클러스터
ES 특징
- Scale out: 샤드를 통해 규모가 수평적으로 늘어날 수 있음
- 고가용성: replica를 통해 데이터 안정성 보장
- Schema Free: json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없음
- Restful: 데이터 CRUD 작업은 HTTP Restful API를 통해 수행함
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
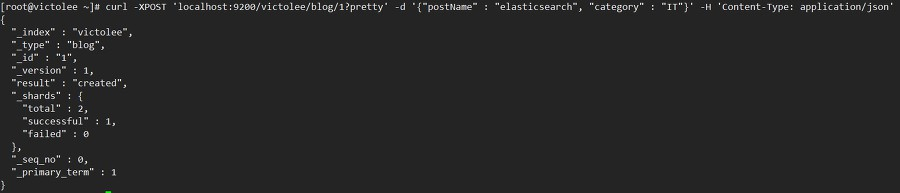
예시 (document (row) 생성)
1
# curl -XPOST 'localhost:9200/victolee/blog/1?pretty' -d '{"postName" : "elasticsearch", "category" : "IT"}' -H 'Content-Type: application/json'
-d 옵션
- 추가할 데이터를 json 포맷으로 전달합니다.
-H 옵션
- 헤더를 명시합니다. 예제에서는 json으로 전달하기 위해서 application/json으로 작성했습니다.
?pretty
- 결과를 예쁘게 보여주도록 요청
결과:
- 이렇게 curl 요청을 하면, victolee 인덱스에, blog 타입으로 id 값이 1인 document가 저장됨
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
- 이렇게 curl 요청을 하면, victolee 인덱스에, blog 타입으로 id 값이 1인 document가 저장됨
역색인 (Inverted Index)
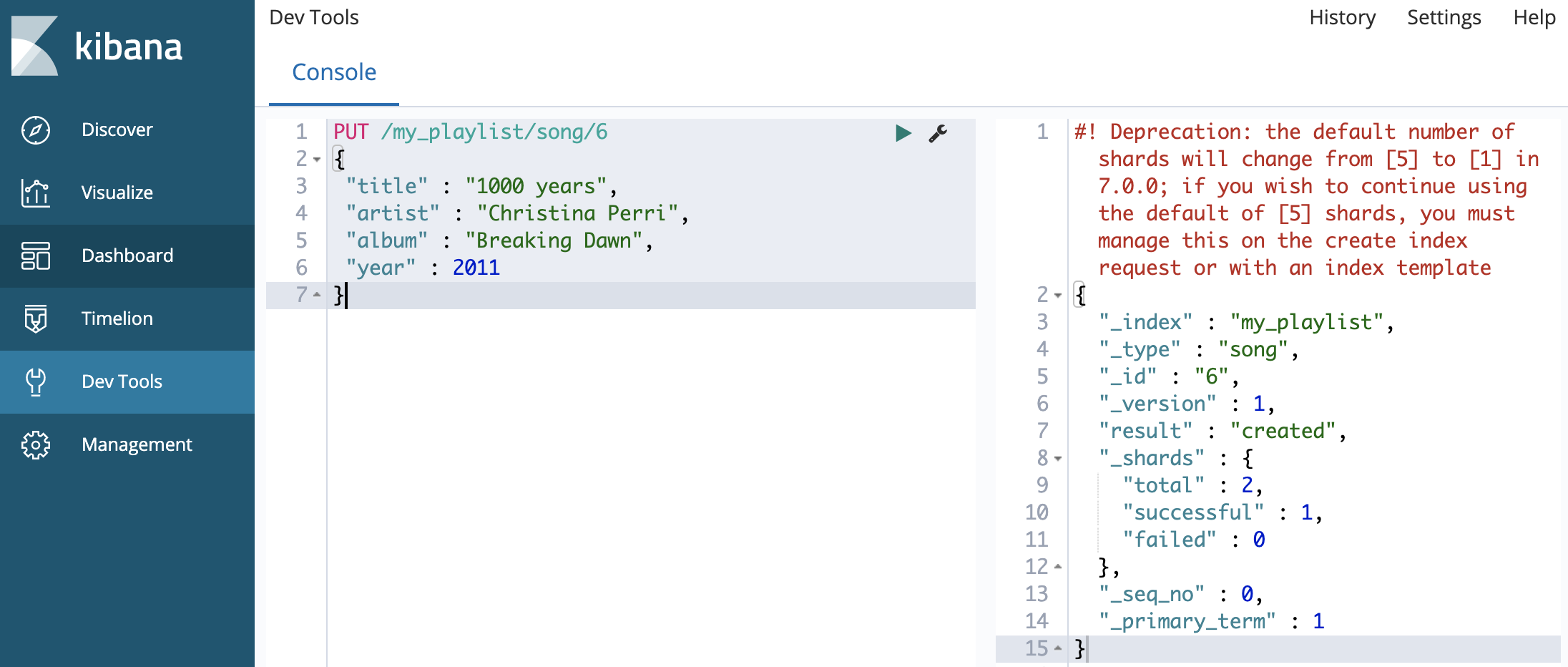
키바나에서 데이터 삽입 예제
1
2
3
4
5
6
7PUT /my_playlist/song/6
{
"title" : "1000 years",
"artist" : "Christina Perri",
"album" : "Breaking Dawn",
"year" : 2011
}명령어 설명
- my_playlist : 여러분의 데이터가 들어갈 인덱스의 이름입니다.
- song : 만들어질 document의 이름입니다.
- 6 : 엘리먼트 인스턴스의 아이디입니다. 이 경우에는 song id입니다.
만일 my_playlist가 존재하지 않았다면, 새로운 인덱스인 my_playlist가 만들어짐. document인 song과 id인 6도 똑같이 만들어짐.
값을 업데이트 하기 위해서는 PUT 명령어를 동일한 document에 사용하면 됨. 새로운 필드도 추가 가능함
 {: height=”50%” width=”50%”}
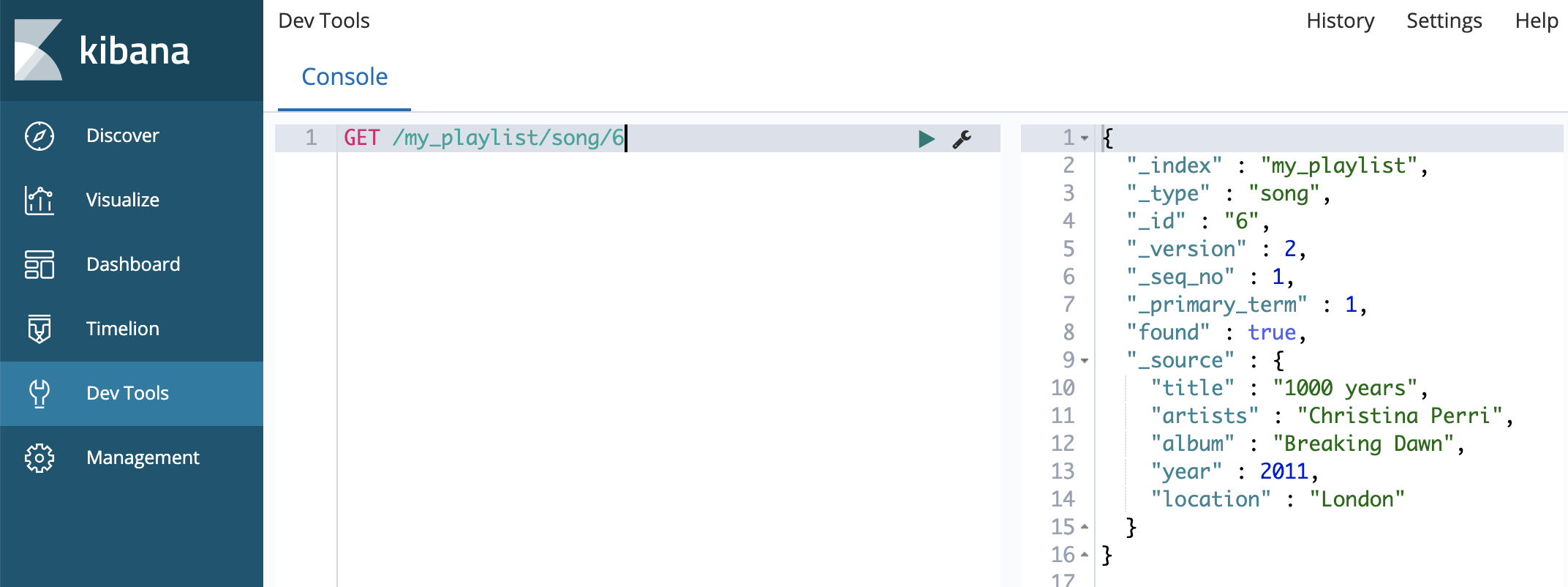
{: height=”50%” width=”50%”}GET 명령어 쓰면 값 불러옴
1
GET /my_playlist/song/6
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}데이터 선택하는 조건문 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14# state가 UT인 데이터 가져오기
GET /bank/_search?q=state:UT
# state가 UT이거나 CA인 데이터 가져오기
GET /bank/_search?q=state:UT OR CA
# state가 TN이면서 여성(female)인 데이터 가져오기
GET /bank/_search?q=state:TN AND gender:F
# 20살보다 많은 나이를 가진 사람들 가져오기
GET /bank/_search?q=age:>20
# 20살과 25살 사이의 데이터 가져오기
GET /bank/_search?q=age:(>=20 AND <=25)좀 더 복잡한 질의
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# address 필드에서 Street이라는 단어가 포함되어야 함
# gender 필드에서 f가 정확히 일치하여야 함
# age 필드에서 숫자는 25보다 크거나 같아야 함
GET /_search
{
"query": { //1
"bool": { //2
"must": [
{ "match":{"address":"Street"}} //3
],
"filter": [ //4
{ "term":{"gender":"f"}}, //5
{ "range": { "age": { "gte": 25 }}} //6
]
}
}
}
Kibana
- 데이터는 ES에 올라가 있어야함
- ES 인덱스(DB)에 저자된 데이터를 키바나가 인식할 수 있도록 인덱스를 설정해야함
데이터 복구
- 스냅샷을 이용해야함~!
- https://kay0426.tistory.com/46