Universal Language Model Fine-tuning for Text Classification (ULMFiT)
Author
- 저자:Jeremy Howard, Sebastian Ruder (fast.ai University of San Francisco)
Who is an Author?
- Google Scholar에 안나와서..
- Author’s Twitter
느낀점
- pretrained model을 범용적으로 쓰려고 시도하려는 시기의 초기 논문인것 같다
- 저자가 어필을 되게 많이 하는 듯
- 각 레이어마다 feature가 다르니 다르게 finetune시켜줘야한다는 아이디어가 검증하긴 좀 어렵지만 직관적으론 꽤 설득력있었음. 한편으론 꼭 그래야되나 싶긴하면서도 나쁘지 않았던?
- warm up등 테크닉이 여기서부터 점점 변형되면서 제안되는 듯
Abstract
- transfer learning(CV에서 큰 임팩트를 줬던)이 NLP에서는 task-specific modification이 필요하거나 scratch에서 다시 학습해야했음 (2018년이라는걸 기억하자)
- 이를 개선하기 위해 Universal한 구조로 모델을 만듬 (ULMFiT)
- 6개의 텍스트 분류문제에서 SOTA 찍고, 18-24% error를 낮춤
- 오직 100개의 라벨된 데이터로 100배는 많은 데이터로 학습한 모델과 비슷한 성능을 냄
1. Introduction
- 기존 NLP 에서는 transductive learning (semi-supervised learning)에 집중해왔음 (transductive vs inductive)
- inductive learning의 예로 pretrained word embedding은 좋은 성과를 냈음
- inductive learning의 핵심은 좋은 random initialization이지만 이게 NLP에서 잘 안돼왔음
- Dai and Le (2015)은 처음으로 LM을 fine-tune하는 방법을 제안해지만 이 방법을 위해선 수백만의 코퍼스가 필요했음
- CV쪽 모델에 비해 NLP쪽은 Shallow한 모델이니 다른 방법의 finetune이 요구됨
- Universal Language Model Fine-tuning (ULMFiT) 모델을 제안함
- 3-layer LSTM architecture로 다른 engineered models를 이김
- 예를 들면,
On IMDb, with 100 labeled examples, ULMFiT matches the performance of training from scratch with 10× and—given 50k unlabeled examples—with 100× more data - Contribution:
- propose Universal Language Model Fine-tuning (ULMFiT), a method that can be used to achieve
CV-like transfer learning - propose discriminative fine-tuning, slanted triangular learning rates, and gradual unfreezing, novel techniques
to retain previous knowledge and avoid catastrophic forgettingduring fine-tuning outperform the state-of-the-art on six representative text classificationdatasets, with an error reduction of 18-24% on the majority of datasets- extremely sample-efficient transfer learning and perform an extensive ablation analysis
- make the pretrained models and our code available to enable wider adoption
- propose Universal Language Model Fine-tuning (ULMFiT), a method that can be used to achieve
2. Related work
- Transfer learning in CV
- Hypercolumns
- Multi-task learning
- Fine-tuning
3. Universal Language Model Fine-tuning
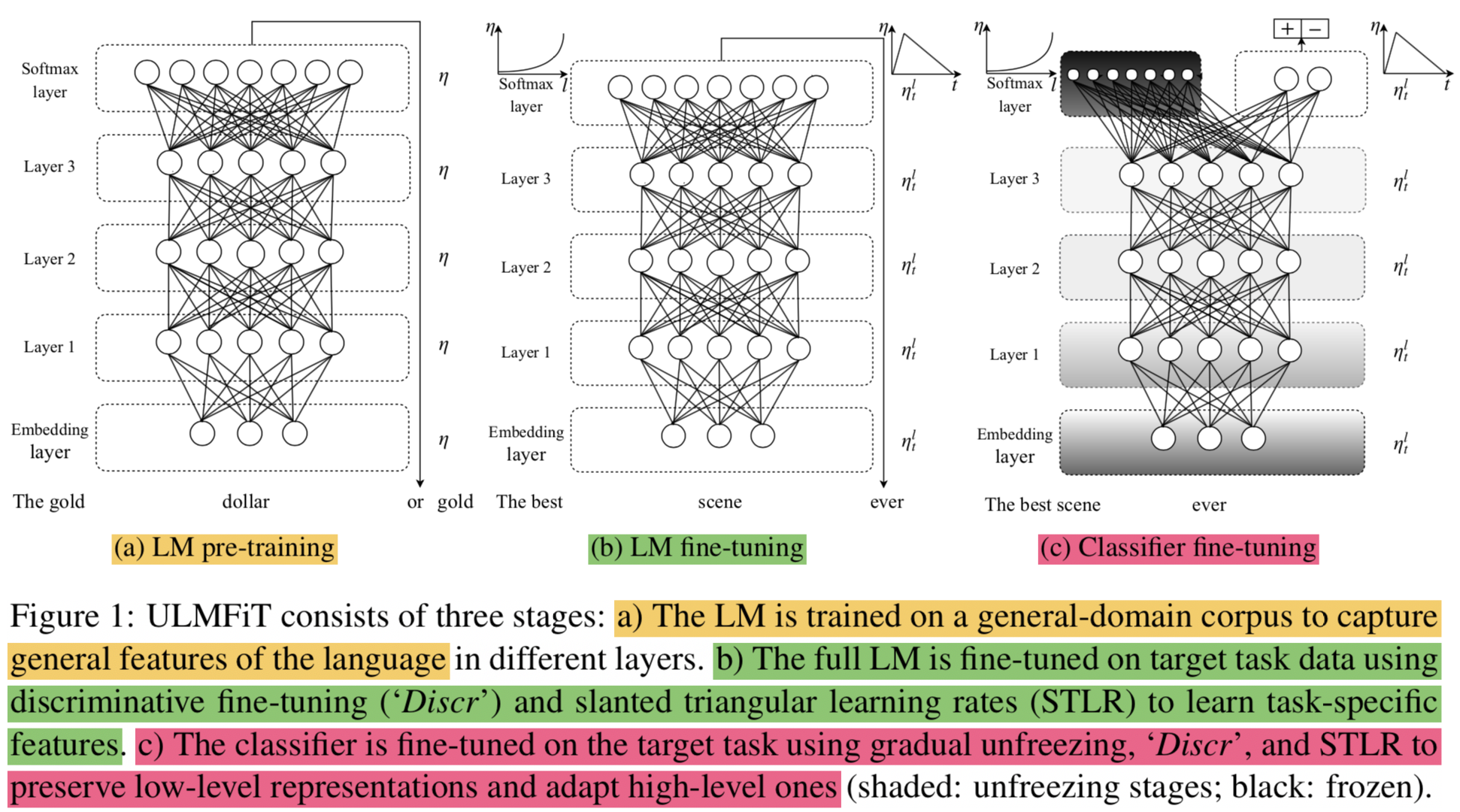 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
- Given static source task $ \mathcal{T}{S} $ 가 있고 any target task $ \mathcal{T}{T} $ 가 있다고 할 때, $ \mathcal{T}{S} \neq \mathcal{T}{T} $ 라고 정의
- 이때 우리의 목표는 $ \mathcal{T}_{T} $의 성능을 높이는 것이다.(도메인 다르다고 생각하면 됨, 언어모델 태스크 -> 텍스트분류 태스크)
a pretrained LM can be easily adapted to the idiosyncrasies of a target- 제안하는 모델은 large general-domain corpus에서 LM을 pretrain하고 target task에 대해서 몇가지 기술들을 적용해서 fine-tune함
- SOTA LM 모델인 AWD-LSTM (Merity et al., 2017a), a regular LSTM (with no attention, short-cut connections, or other sophisticated ad- ditions) 모델을 사용함
- 제안 모델을 구성하는 스텝들
- 일반 도메인에 대해 LM 학습
- 사용하려는 도메인에 대해 LM 튜닝
- 사용하려는 도메인에 대해 classifier 붙여서 튜닝
3.1 General-domain LM pretraining
- LM 학습 데이터: Wikitext-103 (Merity et al., 2017b) consisting of 28,595 preprocessed Wikipedia articles and 103 million words
- 특징:
- 단점: While this stage is the most expensive,
- 장점: it only needs to be performed once and improves perfor- mance and convergence of downstream models
3.2 Target task LM fine-tuning
- general domain에 대해서 pretrain해도 target data는 다른 분포를 갖고 있음
- 그러므로 target data에 대해서 fine-tune 해야함
- 이 작업 수행하면 small dataset에 대해서도 잘 학습됨
- 본 논문에서는 discriminative fine-tuning and slanted triangular learning rates for fine-tuning the LM 기법을 제안함
Discriminative fine-tuning
다른 레이어는 다른 타입의 정보를 캐치함 (
As different layers capture different types of information (Yosinski et al., 2014))그러므로 다르게 fine-tune 되야한다고 주장
모든 레이어에 같은 lr 을 적용하는게 아니라 다르게 적용!(실제로 이게 의미 있는지 궁금하긴 하네)보통 SGD 식은 아래와 같음
$$
\theta_{t}=\theta_{t-1}-\eta \cdot \nabla_{\theta} J(\theta)
$$제안하는 방법의 식은 아래와 같음
$$
\theta_{t}^{l}=\theta_{t-1}^{l}-\eta^{l} \cdot \nabla_{\theta^{l}} J(\theta)
$$모델의 파라미터를 다음과 같이 $
\theta \text { into }\left{\theta^{1}, \ldots, \theta^{L}\right} $ 각 레이어에 해당되는 파라미터로 레이어 notation을 통해 나타낼 수 있음각 레이어의 모델 파라미터는 각 레이어에 맞는 lr로 업데이트 된다는게 위에서 제안하는 방법임
$ {\eta^{l-1}=} {\eta^{l} / 2.6} $ 공식으로 lr을 실험적으로 정함
Slanted triangular learning rates
빠르게 수렴시키기 위해서 고정된 lr을 쓰거나 annealed lr을 사용하는건 best way가 아닐 수 있음
Slanted triangular learning rates(STLR)을 제안함
- 처음엔 linear하게 증가했다가 추후 작아짐 (
warm up이랑 거의 똑같네?) - T: num of training iteration
- cut_frac: the fraction of iterations
cut: the iteration when we switch from increasing to decreasing the LR- p: the fraction of the number of iterations we have increased or will decrease the LR respectively
- STLR modifies triangular learning rates (Smith, 2017) with a short increase and a long decay period (CV에서 썼던 기법)
$$
\begin{aligned} c u t &=\left\lfloor T \cdot c u t_{-} f r a c\right\rfloor \ p &=\left{\begin{array}{ll}{t / c u t,} & {\text { if } t<c u t} \ {1-\frac{t-c u t}{c u t \cdot(1 / 1 c u t-f r a c-1)},} & {\text { otherwise }} \end{array} \right. \ {\eta_{t}} & {=\eta_{\max } \cdot \frac{1+p \cdot(\text {ratio }-1)}{\text {ratio}}} \end{aligned}
$$- 처음엔 linear하게 증가했다가 추후 작아짐 (
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
7. Conclusion
- transfer learning에 효과적이고 효율적인 모델인 ULMFiT을 제안함
- 몇가지 fine-tuneing technique도 제안함 (prevent catastrophic forgetting, enable robust learning)
- 기존 transfer learning technique보다 낫고, 6개 분류 태스크에서 SOTA 찍음
Universal Language Model Fine-tuning for Text Classification (ULMFiT)
https://eagle705.github.io/2019-10-11-UniversalLMFinetuneforTextClf/