SELF-INSTRUCT Aligning Language Model with Self Generated Instructions
Note
- code: https://github.com/yizhongw/self-instruct
- slide: SELF-INSTRUCT.pdf
- 여기 있는 Instruction은 NLP task쪽이라기보다 InstructGPT에서의 prompt중에 명령관련 표현을 의미하는 듯
- Instruction뿐만 아니라 Instance도 생성하기 때문에 challenge하고, LLM에 내재되어있는 능력을 꺼내되 꺼낸 컨텐츠도 LLM안에 있는거라서, human의 개입이 잘안들어간 self-Instruct+Instance라고 할 수 있을듯
- Because of SELF-INSTRUCT’s dependence on the inductive biases extracted from LMs
- InstructGPT_001 정도의 모델을 휴먼리소스 적게해서 만드는 방법
- 175개 시드 템플릿
| 예시1 | 예시2 |
|---|---|
 |
 |
Author
- Yizhong Wang♣ Yeganeh Kordi♢ Swaroop Mishra♡ Alisa Liu♣ Noah A. Smith♣+ Daniel Khashabi♠ Hannaneh Hajishirzi♣+
- ♣University of Washington ♢Tehran Polytechnic ♡Arizona State University ♠Johns Hopkins University +Allen Institute for AI
Abstract
- Large “instruction-tuned” language models (finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks.
- Nevertheless, they depend heavily on human-written instruction data that is limited in quantity, diversity, and creativity, therefore hindering the generality of the tuned model.
- We introduce SELF-INSTRUCT, a framework for improving the instruction-following capabilities of pretrained language models by bootstrapping off its own generations.
- Our pipeline
- generates
- instruction,
- input, and
- output samples
- from a language model, then prunes them before using them to finetune the original model.
- generates
- Applying our method to vanilla GPT3, we demonstrate a 33% absolute improvement over the original model on SUPERNATURALINSTRUCTIONS, on par with the performance of InstructGPT001
- we curate a set of expert-written instructions for novel tasks, and show through human evaluation that tuning GPT3 with SELF-INSTRUCT outperforms using existing public instruction datasets by a large margin, leaving only a 5% absolute gap behind InstructGPT001
- SELF-INSTRUCT provides an almost annotation-free method for aligning pretrained language models with instructions, and we release our large synthetic dataset to facilitate future studies on instruction tuning.
Introduction
- These developments are powered by two key components: large pre-trained language models (LM) and human-written instruction data. PROMPTSOURCE (Bach et al., 2022) and SUPERNATURALINSTRUCTIONS (Wang et al., 2022) are two notable recent datasets that use extensive manual annotation for collecting instructions to construct T0 and T𝑘-INSTRUCT
- However, this process is costly and often suffers limited diversity given that most human generations tend to be popular NLP tasks, falling short of covering a true variety of tasks and different ways to describe them.
- In this work, we introduce SELF-INSTRUCT, a semi-automated process for instruction-tuning a pretrained LM using instructional signals from the model itself.
- The overall process is an iterative bootstrapping algorithm (see Figure 1), which starts off with a limited (e.g., 175 in our study) seed set of manually-written instructions that are used to guide the overall generation.
- In the first phase, the model is prompted to generate instructions for new tasks
- This step leverages the existing collection of instructions to create more broad-coverage instructions that define (often new) tasks
- Given the newly-generated set of instructions, the framework also creates input-output instances for them, which can be later used for supervising the instruction tuning.
- Finally, various measures are used to prune low-quality and repeated instructions, before adding them to the task pool. (어떤 measure를 쓰는건지 봐야겠군)
- This process can be repeated for many interactions until reaching a large number of tasks.

- This process can be repeated for many interactions until reaching a large number of tasks.
- In the first phase, the model is prompted to generate instructions for new tasks
- The iterative SELF INSTRUCT process on this model leads to about
52k instructions,paired with about 82K instance inputs and target outputs.- 인스터럭션이 5만2천개고, 실제 데이터는 8만2천개라는거지?
- provides a diverse range of creative tasks and over 50% of them have less than 0.3 ROUGE- L overlaps with the seed instructions (§4.2)
- rouge-l 기준 0.3보다 낮아서 안겹친다는건데, 이게 의미적으로 맞긴한거냐고
- The SUPERNI results indicate that GPT3SELF-INST out- performs GPT3 (the original model) by a large margin (+33.1%) and nearly matches the performance of InstructGPT001
- Moreover, our human evaluation on the newly-created instruction set shows that GPT3SELF-INST demonstrates a broad range of instruction following ability, outperforming models trained on other publicly available instruction datasets and leaving only a 5% gap behind InstructGPT001.
- In summary, our contributions are:
- (1) SELF-INSTRUCT, a method for inducing instruction following capability with minimal human-labeled data;
- (2) We demonstrate its effectiveness via extensive instruction-tuning experiments;
- (3) We release a large synthetic dataset of 52K instructions and a set of manually-written novel tasks for building and evaluating future instruction-following models.
Method
- Annotating large-scale instruction data can be challenging for humans because it requires
- creativity to come up with novel tasks and
- expertise for writing the labeled instances for each task.
Defining Instruction Data

Automatic Instruction Data Generation
- Our pipeline for generating the instruction data consists of four steps:
- instruction generation,
- identifying whether the instruction represents a classification task or not, (왜 분류 태스크인지 아닌지를 알아내려할까?)
- instance generation with the input-first or the output-first approach, and
- filtering low-quality data.
Instruction Generation
- large pretrained language models can be prompted to generate new and novel instructions when presented with some existing instructions in the context
- This provides us with a way to grow the instruction data from a small set of seed human-written instructions
- We propose to generate a diverse set of instructions in a bootstrapping fashion
- We initiate the task pool with 175 tasks (1 instruction and 1 instance for each task) written by our authors
- For every step, we sample 8 task instructions from this pool as in-context examples
- Of the 8 instructions, 6 are from the human-written tasks, and 2 are from the model-generated tasks in previous steps to promote diversity.
- The prompting template is shown in Table 6.
- 6개는 사람이 쓴거고 2개는 모델이 생성한건데, 음.. 초기에 저렇게 한다는걸까

Classification Task Identification.
- Because we need two different approaches for classification and non-classification tasks, we next identify whether the generated instruction represents a classification task or not.
- We prompt vanilla GPT3 few-shot to determine this, using 12 classification instructions and 19 non-classification instructions from the seed tasks.
- few-shot으로 이게 classification인지 아닌지 판단하게함, few-shot이 좋아야하네, practical하다고 할수 있을까?
- We prompt vanilla GPT3 few-shot to determine this, using 12 classification instructions and 19 non-classification instructions from the seed tasks.
Instance Generation.
- Given the instructions and their task type, we generate instances for each instruction independently.
- 각각에 대해서 생성하는건 잘한듯
- This is challenging because it requires the model to understand what the target task is, based on the instruction, figure out what additional input fields are needed and generate them, and finally complete the task by producing the output.
- pretrained language models can achieve this to a large extent when
prompted with instruction-input-output in-context examplesfrom other tasks - A natural way to do this is the
Input-first Approach- language model to come up with the input fields first based on the instruction, and then produce the corresponding output.
- However, we found that this approach can generate inputs biased toward one label, especially for classification tasks (e.g., for grammar error detection, it usually generates grammatical input). Therefore, we additionally propose an
Output-first Approachfor classification tasks- we first generate the possible class labels, and then condition the input generation on each class label.
- We apply the
output-first approachto theclassification tasksidentified in the former step, and theinput-first approachto theremaining non-classification tasks.- 분류문제와 비분류문제에 대해서는 접근을 다르게함
Filtering and Postprocessing
- To encourage diversity, a new instruction is added to the task pool only when its
ROUGE-L overlapwith any existing instruction isless than 0.7.- instruction이 많은데 검수를 꽤 해야겠네 (루프한번이면 되지만)
- We also exclude instructions that contain some specific keywords (e.g., images, pictures, graphs) that usually can not be processed by language models.
- 이미지, 그래프등의 단어는 룰로 배제
- When generating new instances for each instruction, we filter out instances that are exactly the same or those with the same input but different outputs.
- Q) 이상한 Instruction이랑 Instance가 분명 있을텐데 왜 얘넨 필터링 안하지?
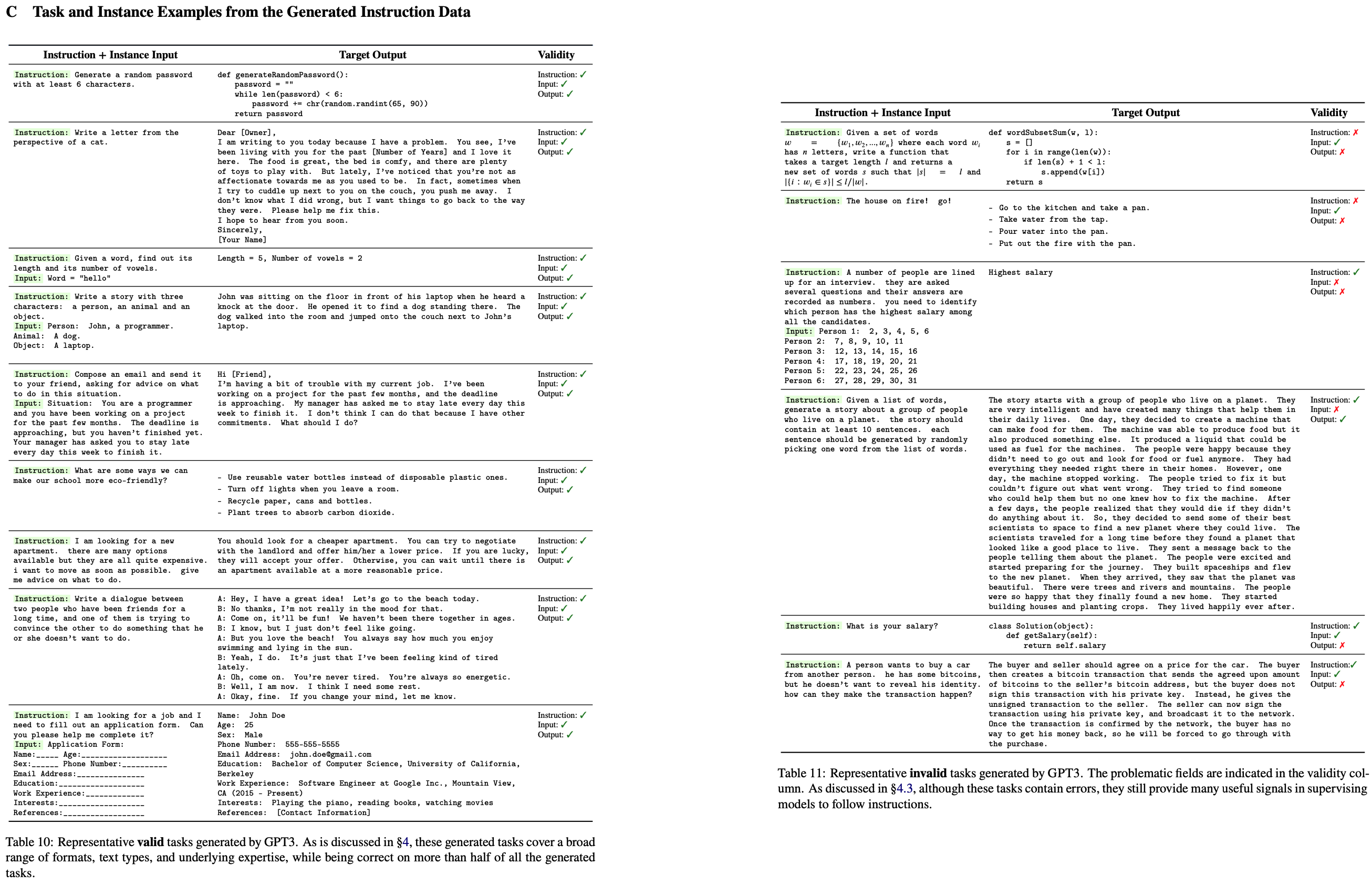
| Table 7 | Table 8 | Table 9 |
|---|---|---|
 |
 |
 |
Finetuning the LM to Follow Instructions
- After the creation of the large-scale instruction data, we use this data to finetune the original language model (i.e., SELF-INSTRUCT).
- To do this, we
concatenate the instruction and instance input as a promptandtrain the model to generate the instance outputin a standardsupervisedway. - To make the model
robustto different formats, we usemultipletemplates to encode the instruction and instance input together.- For example, the instruction can be prefixed with
“Task:” or not, the input can be prefixed with“Input:” or not,“Output:” can be appended at the end of the prompt, and different numbers of break lines can be put in the middle, etc.
- For example, the instruction can be prefixed with
SELF-INSTRUCT Data from GPT3
- we apply our method for inducing instruction data to GPT3 as a case study
- We use the largest GPT3 language model (“davinci” engine) accessed through the OpenAI API
- 아.. API 써서 한거구나
Statistics
- We generate a total of over 52K instructions, and more than 82K instances corresponding to these instructions after filtering.
- 인스트럭션이 52,000개인데 인스턴스는 82,000이네 더 많이 만들고(텍스트야 모델돌리면 생성되니) 필터링했다는 걸까

- 인스트럭션이 52,000개인데 인스턴스는 82,000이네 더 많이 만들고(텍스트야 모델돌리면 생성되니) 필터링했다는 걸까
Diversity
- we identify the verb-noun structure in the generated instructions. We use the Berkeley Neural Parser6 (Kitaev and Klein, 2018; Kitaev et al., 2019) to parse the instructions, and then extract the verb that is closest to the root of the parse tree as well as its first direct noun object. 26,559 out of the 52,445 instructions contain such structure; other instructions usually contain more complex clauses (e.g., “Classify whether this tweet contains political content or not.”) or are framed as questions (e.g., “Which of these statements are true?”).
- We plot the top 20 most common root verbs and their top 4 direct noun objects in Figure 2, which accounts for 14% of the entire set. Overall, we see quite diverse intents and textual formats in these instructions.
- For each generated instruction, we compute its highest ROUGE-L overlap with the 175 seed instructions. We plot the distribution of these ROUGE-L scores in Figure 3,
- 시드에 대해서만 계산했구나
- We also demonstrate diversity in length of the instructions, instance inputs, and instance outputs in Figure 4.

Quality
- To investigate this, we
randomly sample 200 instructionsandrandomly select 1 instance per instruction. We asked an expert annotator (co-author of this work) to label whether each instance is correct or not, in terms of the instruction, the instance input, and the instance output. Evaluation results in Table 2 show that most of the generated instructions are meaningful, while the generated instances may contain more noise (to a reasonable extent). - However, we found that
even though the generations may contain errors, most of them are still in the correct format or even partially correct, which can provideuseful guidance for trainingmodels to follow instructions- 표를 보면 아웃풋이 인스트럭션과 인풋에 대해서 적합하냐 했을때 58%… 이거 써도 되는걸까

Experimental Results
GPT3SELF-INST: fine-tuning GPT3 on its own instruction data
- We use the default hyper-parameters, except that we set the prompt loss weight to 0, and we train the model for 2 epochs.
- The resulting model is denoted as GPT3SELF-INST.
Baselines
Off-the-shelf LMs
- T5-LM, GPT3
- These baselines will indicate the extent to which off-the-shelf LMs are capable of following instructions naturally immediately after pretraining.
Publicly-available instruction-tuned models
- T0 and T𝑘-INSTRUCT are two instruction-tuned models proposed in Sanh et al. (2022) and Wang et al. (2022)
- For both of these models, we use their largest version with 11B parameters.
Instruction-tuned GPT3 models
- We evaluate InstructGPT (Ouyang et al., 2022), which is developed by OpenAI based on GPT3 to follow human instructions better and has been found by the community to have impressive zero-shot abilities
- (we only compare with their text-davinci-001 engine)
Experiment 1: Zero-Shot Generalization on SUPERNI benchmark

Experiment 2: Generalization to User-oriented Instructions on Novel Tasks
most of these NLP tasks were proposed for research purposes and skewed toward classification. To better access the practical value of instruction-following models, a subset of the authors curate a new set of instructions motivated by user-oriented applications- craft instructions related to each domain(e.g., email writing, social media, productivity tools, entertainment, programming) along with an input-output instance (again, input is optional)
- In total, we create
252 instructionswith 1 instance per instruction. We believe it can serve as a testbed for evaluating how instruction based models handle diverse and unfamiliar instructions. Table 4 presents a small portion of the 252 tasks.

Human evaluation setup

Discussion and Limitation
Why does SELF-INSTRUCT work?
- we conjecture that it is closer to 𝐻2, particularly for larger models
- LMs already know much about language instructions, is a key motivation for SELF- INSTRUCT and is also supported by its empirical success.
| (H1) 첫번째 가설 | (H2) 두번째 가설 |
|---|---|
| Human feedback is a necessary and indispensable aspect of instruction-tuning as LMs need to learn about issues that were not quite learned during pre-training. | Human feedback is an optional aspect of instruction tuning as LMs are already quite familiar with instructions from their pre-training. Observing the human feedback is merely a lightweight process for aligning their pre-training distribution/objective which might be replaceable with a different process. |
Limitations of SELF-INSTRUCT
Tail phenomena
- LMs’ largest gains correspond to the frequent uses of languages (head of the language use distribution), and there are minimal gains in the low-frequency contexts
- Similarly, in the context of this work, it would not be surprising if the majority of the gains by SELF-INSTRUCT are skewed toward tasks or instructions that present
more frequently in the pre-training corpus
Dependence on large models.
- Because of SELF-INSTRUCT’s dependence on the inductive biases extracted from LMs, it might work best for larger models
Reinforcing LM biases.
- the unintended consequences of this
iterative algorithm, such as the amplification of problematic social biases (stereotypes or slurs about genders, races, etc.) - Relatedly, one observed
challengein this process is the algorithm’sdifficulty in producing balanced labels, which reflected models’ prior biases
Conclusion
- We introduce SELF-INSTRUCT, a task-agnostic method to improve the instruction-following capabilities of language models via its own generation of in

struction data (instruction, input, and output samples) and bootstrapping with it
한글도 된다?!


SELF-INSTRUCT Aligning Language Model with Self Generated Instructions
https://eagle705.github.io/SELF-INSTRUCT Aligning Language Model with Self Generated Instructions/