Toolformer: Language Models Can Teach Themselves to Use Tools
Note
- 미리 학습데이터를 API 기반으로 생성해놓되, 생성할때는 loss에 도움이 되는 방향으로 구성해놓고, 실제 인퍼런스할때 API콜과 관련된 토큰이 나오면 잠시 디코딩 중지 후 API콜하고 결과 받아온다음에 다시 이어서하는 방식!
- API종류가 많진 않아서, 완전 범용적인 평가라 하기엔 애매하고 약간 무거운것 같기도하나(학습과정이), 실제 사용할땐 편할수도
- 공개된 레포는 없지만, lucidrains가 만들기 시도 (https://github.com/lucidrains/toolformer-pytorch)
- paper: Toolformer Language Models Can Teach Themselves to Use Tools.pdf
- 자세한 내용은 slide 참고: Toolformer.pdf
Author
- Timo Schick Jane Dwivedi-Yu Roberto Dessì† Roberta Raileanu Maria Lomeli Luke Zettlemoyer Nicola Cancedda Thomas Scialom
Meta AI Research†Universitat Pompeu Fabra
Abstract
- They also, paradoxically, struggle with basic functionality, such as arithmetic or factual lookup, where much simpler and smaller models excel.
- In this paper, we show that LMs can teach themselves to use
external tools via simple APIsand achieve the best of both worlds. - We introduce
Toolformer, a modeltrained to decide which APIs to call,when to callthem,what arguments to pass, andhow to best incorporate the results into future token prediction.- 이게 이 논문의 핵심이네, 어떤 API를 콜할지, 언제 콜할지, 어떤 args를 넣을지 어떻게 future token 예측에 쓸건지를 고르는 것!
- This is done in a self-supervised way,
requiring nothing more than a handful of demonstrations for each API - We incorporate a range of tools, including a calculator, a Q&A system, a search engine, a translation system, and a calendar.
- Toolformer achieves substantially improved zero-shot performance across a variety of downstream tasks, often competitive with much larger models, without sacrificing its core language modeling abilities.
Introduction
- However, all of these models have several inherent limitations that can at best be partially addressed by further scaling. These limitations include an inability to access up-to-date information on recent events and the related tendency to hallucinate facts
- LLMs은 크기가 커야되는데, 이러면 최신정보 업데이트가 어렵다
- hallucinate 문제가 따라다닌다
- difficulties in understanding low-resource languages
- a lack of mathematical skills to per- form precise calculations
- unawareness of the progression of time
- 이러한 이슈를 극복하기 위해선 external tools을 사용해볼 수 있음
- A simple way to overcome these limitations of today’s language models is to give them the ability to use external tools such as search engines, calculators, or calendars.
- 하지만 기존 연구는 많은 양의 휴먼 어노테이션에 의존하거나, task-specific settings에 기반해서 다양한 적용이 어려웠음
- However, existing approaches either rely on large amounts of human annotations (Komeili et al., 2022; Thoppilan et al., 2022) or limit tool use to task-specific settings only (e.g., Gao et al., 2022; Parisi et al., 2022), hindering a more widespread adoption of tool use in LMs.
- Toolformer를 제안하고 아래와 같은 조건을 만족시킴
- The use of tools should be learned in a self-supervised way without requiring large amounts of human annotations.
- The LM should not lose any of its generality and should be able to decide for itself when and how to use which tool.
- Our approach for achieving these goals is based on the recent idea of using large LMs with in-context learning (Brown et al., 2020) to generate entire datasets from scratch
- 아이디어 자체는
in context learning에 기반한다- Given just a handful of human-written examples of how an API can be used, we let a LM annotate a huge language modeling dataset with potential API calls.
- We then use a self-supervised loss to determine which of these API calls actually help the model in predicting future tokens
- Finally, we finetune the LM itself on the API calls that it considers useful.
- 아이디어 자체는

- As our approach is agnostic of the dataset be- ing used, we can apply it to the exact same dataset that was used to pretrain a model in the first place. This ensures that the model does not lose any of its generality and language modeling abilities.
- Toolformer, which is based on a pretrained
GPT-J model (Wang and Komatsuzaki, 2021) with 6.7B parameters, achieves much stronger zero-shot results, clearly outperforming a much larger GPT-3 model
Approach
- This allows seamless insertion of API calls into any given text, using
special tokensto mark the start and end of each such call.


- This is done in three steps, illustrated in Figure 2:
- First, we exploit the in-context learning ability of M to sample a large number of potential API calls.
- We then execute these API calls and finally check whether the obtained responses are helpful for predicting future tokens
- this is used as a filtering criterion
- After filtering, we merge API calls for different tools, resulting in the augmented dataset C∗ and finetune M itself on this dataset

Sampling API Calls
- we write a prompt P(x) that encourages the LM to annotate an example x = x1,…,xn with API calls.
- 아래 그림과 같이 정답이 있는 지문에 대해서 prompt를 사람이 생성하고, 이걸 학습시켜서 api 맵핑 및 호출시키는건가? 조금 더 확인해보자
- 확률기반으로 api 콜링을 할만한 k개의 후보 포지션을 샘플링하고(API 스페셜토큰 생성확률이 높은!) -> 각 포지션마다 api 종류중에 확률이 높은 m개를 또 샘플링한다
</API>를 eos 토큰으로 썼기 때문에 이거 없는 샘플은 버린다
| Sampling API Calls | Figure 3 |
|---|---|
 |
 |
Executing API Calls
- API 후보들을 실행한다
- we execute all API calls generated by M to obtain the corresponding results.
- API 실행은 API 종류에 따라 다양하다
- How this is done depends entirely on the API itself – for example, it can involve calling another neural network, executing a Python script or using a retrieval system to perform search over a large corpus.
Filtering API Calls

Model Finetuning
- After sampling and filtering calls for all APIs, we finally merge the remaining API calls and interleave them with the original inputs
- e(c_i,r_i)가 prefix로 제공된다는게 무슨뜻일까?
| Model Finetuning_1 | Model Finetuning_2 |
|---|---|
 |
 |
Inference
- we perform regular decoding until M produces the
“→” token, indicating that it next expects the response for an API call - At this point, we
interrupt the decoding process, call the appropriate API to get a response, and continuethe decoding process after inserting both the response and the token.
Tools
- The only constraints we impose on these tools is that
- (i) both their inputs and outputs can be represented as
text sequences, and - (ii) we can obtain a
few demonstrationsof their intended use.
- (i) both their inputs and outputs can be represented as
- we explore the following five tools:
- a question answering system,
- Our first tool is a question answering system based on another LM that can answer simple factoid questions. Specifically, we use Atlas (Izacard et al., 2022), a retrieval-augmented LM finetuned on Natural Questions
- a Wikipedia search engine,
- given a search term, returns short text snippets from Wikipedia.
- but requires it to extract the relevant parts by itself
- a calculator,
- we only support the four basic arithmetic operations. Results are always rounded to two decimal places
- a calendar, and
- when queried, returns the current date without taking any input
- a machine translation system.
- machine translation system based on a LM that can translate a phrase from any language into English.
- The source language is automatically detected using the fast- Text classifier
- a question answering system,

Experiments
- We investigate whether our approach enables a model to use tools without any further supervision and to decide for itself when and how to call which of the available tools
- To test this, we select a variety of downstream tasks where we assume at least one of the considered tools to be useful, and evaluate performance in zero-shot settings
Experimental Setup
Dataset Generation
- use a subset of CCNet as our language modeling dataset C
- GPT- J (Wang and Komatsuzaki, 2021) as our language model M
- To reduce the computational cost of annotating C with API calls, we define
heuristicsfor some APIs to get a subset of C for which API calls are more likely to be helpful than for an average text.- we only consider texts for the calculator tool if they contain at least three numbers.
- For obtaining C ∗ from C , we perform all steps described in Section 2 and additionally filter out all examples for which all API calls were eliminated in the filtering step.
| weighting func | Table2 |
|---|---|
 |
 |
Model Finetuning
- finetune M on C∗ using a batch size of 128 and a learning rate of 1 · 10−5 with linear warmup for the first 10% of training.
Baseline Models
- GPT-J: A regular GPT-J model without any finetuning.
- GPT-J + CC: GPT-J finetuned on C, our subset of CCNet without any API calls.
- Toolformer: GPT-J finetuned on C∗, our subset of CCNet augmented with API calls.
- Toolformer (disabled): The same model as Toolformer, but API calls are disabled during decoding.
- This is achieved by manually setting the probability of the
token to 0.
- This is achieved by manually setting the probability of the
For most tasks, we additionally compare to OPT (66B) (Zhang et al., 2022) and GPT-36 (175B) (Brown et al., 2020), two models that are about 10 and 25 times larger than our other baseline models, respectively.
Downstream Tasks
- 제로샷 세팅
- In all cases, we consider a prompted zero-shot setup – i.e., models are instructed to solve each task in natural language, but we do not provide any in-context examples.
- We use standard greedy decoding, but with one modification for Toolformer: We let the model start an API call not just when
is the most likely token, but whenever it is one of the k most likely tokens. For k = 1, this corresponds to regular greedy decoding; we instead use k = 10to increase the disposition of our model to make use of the APIs that it has access to. (top k 안에가 생성되도 호출?!) - At the same time, we only at
most one API call per inputto make sure the model does not get stuck in a loop where it constantly calls APIs without producing any actual output.
LAMA
- We evaluate our models on the SQuAD, Google- RE and T-REx subsets of the LAMA benchmark

Math Datasets
- We test mathematical reasoning abilities on ASDiv (Miao et al., 2020), SVAMP (Patel et al., 2021) and the MAWPS benchmark

Question Answering
- We look at Web Questions (Berant et al., 2013), Natural Questions (Kwiatkowski et al., 2019) and TriviaQA (Joshi et al., 2017), the three question answering datasets considered by Brown et al. (2020).

Multilingual Question Answering
- We evaluate Toolformer and all baseline models on MLQA (Lewis et al., 2019), a multilingual question-answering benchmark
- does not consistently outperform vanilla GPT-J. This is mainly because for some languages, finetuning on CCNet deteriorates performance; this might be due to a distribution shift compared to GPT-J’s original pretraining data.
- CCNet에 학습한거 때문이다?!

Temporal Datasets
- To investigate the calendar API’s utility, we evaluate all models on TEMPLAMA (Dhingra et al., 2022) and a new dataset that we call DATESET.
- TEMPLAMA is a dataset built from Wikidata that contains cloze queries about facts that change with time
(e.g., “Cristiano Ronaldo plays for ___”)
Language Modeling
- In addition to verifying improved performance on various downstream tasks, we also want to ensure that language modeling performance of Toolformer does not degrade through our finetuning with API calls.
- 성능 저하 없다구!
- Most importantly, however, training on C∗ (our dataset annotated with API calls) does not lead to an increase in perplexity compared to training on C when API calls are disabled at inference time.8

Scaling Laws
- We investigate how the ability to ask external tools for help affects performance as we vary the size of our LM
- GPT-2 family (Radford et al., 2019), with 124M, 355M, 775M and 1.6B parameters, respectively.

Analysis
Deocidng Strategy
- we generate the
token if it is one of the k most likely tokens - Table 9 shows performance on the T-REx subset of LAMA and on WebQS for different values of k

Data Quality
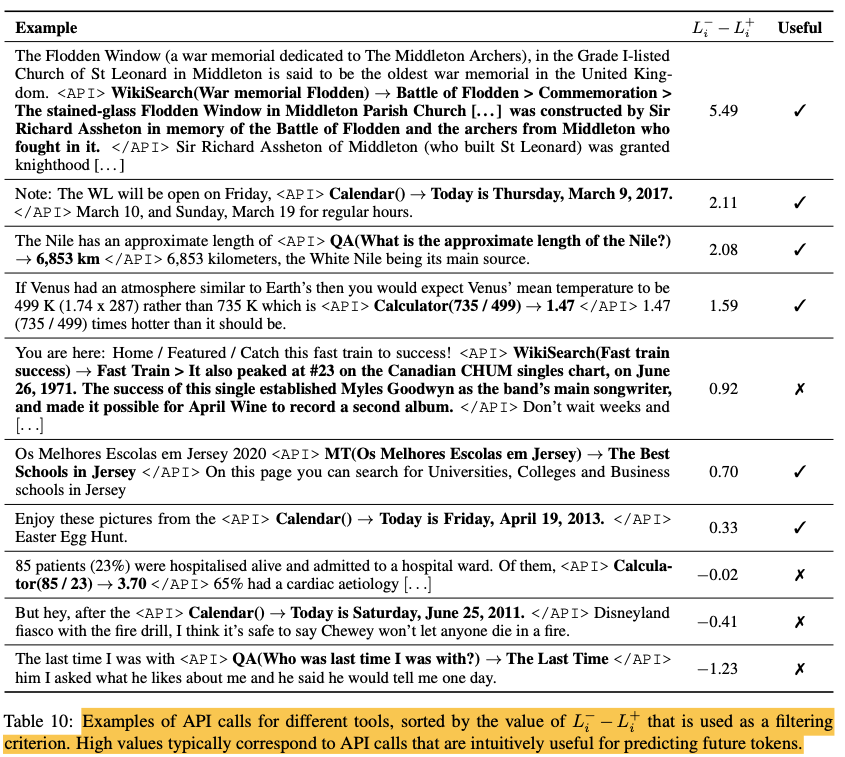
- We qualitatively analyze some API calls generated with our approach for different APIs.
- Table 10 shows some examples of texts from CCNet augmented with API calls, as well as the corresponding score L−i − L+i that is used as a filtering criterion, and whether the API calls made by the model are intuitively useful in the given context.
- However, some amount of noise in the API calls that are not filtered can actually be useful as it forces the model finetuned on C∗ to not always blindly follow the results of each call it makes.
Limitations
- One such limitation is the inability of Toolformer to use tools in a chain (i.e., using the output of one tool as an input for another tool)
- This is due to the fact that API calls for each tool are generated independently
- Our current approach also does not allow the LM to use a tool in an interactive way – especially for tools such as search engines, that could potentially return hundreds of different results, enabling a LM to browse through these results or to refine its search query in a similar spirit to Nakano et al. (2021) can be crucial for certain applications.
- Depending on the tool, our method is also very sample-inefficient; for example, processing more than a million documents results in only a few thousand examples of useful calls to the calculator API.
- Finally, when deciding whether or not to make an API call, Toolformer currently does not take into account the tool-dependent, computational cost incurred from making an API call.
Conclusion
- This is done by finetuning on a large number of sampled API calls that are filtered based on whether they reduce perplexity on future tokens
- Toolformer considerably improves zero-shot performance of a 6.7B parameter GPT-J model, enabling it to even outperform a much larger GPT-3 model on a range of different downstream tasks.
Appendix
B Toolformer Training
- We use up to 25k examples per API. Max sequence length 1,024. Effective batch size of 128. All models are trained using DeepSpeed’s ZeRO-3 (Rasley et al., 2020). We used 8 NVIDIA A100 40GB GPUs with BF16. Training up to 2k steps, where we evaluate PPL on a small development set from CCNet containing 1,000 examples every 500 steps. We pick the checkpoint that performs best.
C Zero-Shot Prompts
- 제로샷이지만 프롬프트줌
- we use the following prompt:
Please complete the following text so that it is factually correct: x.
- we use the following prompt:
Toolformer: Language Models Can Teach Themselves to Use Tools