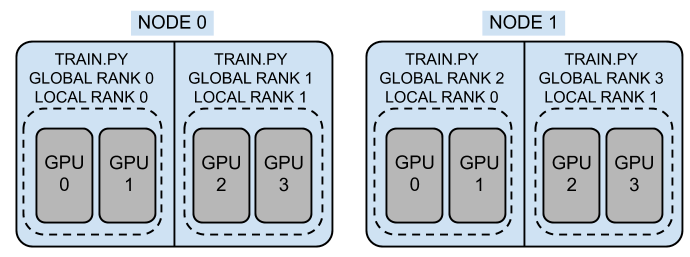
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| def create_optimizer(loss, init_lr, num_train_steps, num_warmup_steps, use_tpu):
"""Creates an optimizer training op."""
global_step = tf.train.get_or_create_global_step()
learning_rate = tf.constant(value=init_lr, shape=[], dtype=tf.float32)
learning_rate = tf.train.polynomial_decay(
learning_rate,
global_step,
num_train_steps,
end_learning_rate=0.0,
power=1.0,
cycle=False)
if num_warmup_steps:
global_steps_int = tf.cast(global_step, tf.int32)
warmup_steps_int = tf.constant(num_warmup_steps, dtype=tf.int32)
global_steps_float = tf.cast(global_steps_int, tf.float32)
warmup_steps_float = tf.cast(warmup_steps_int, tf.float32)
warmup_percent_done = global_steps_float / warmup_steps_float
warmup_learning_rate = init_lr * warmup_percent_done
is_warmup = tf.cast(global_steps_int < warmup_steps_int, tf.float32)
learning_rate = (
(1.0 - is_warmup) * learning_rate + is_warmup * warmup_learning_rate)
optimizer = AdamWeightDecayOptimizer(
learning_rate=learning_rate,
weight_decay_rate=0.01,
beta_1=0.9,
beta_2=0.999,
epsilon=1e-6,
exclude_from_weight_decay=["LayerNorm", "layer_norm", "bias"])
|