Unified Language Model Pre-training for Natural Language Understanding and Generation
Author
- 저자:
- Li Dong∗ Nan Yang∗ Wenhui Wang∗ Furu Wei∗ † Xiaodong Liu Yu Wang Jianfeng Gao Ming Zhou Hsiao-Wuen Hon (Microsoft Research)
Who is an Author?
- 일단 쓴 논문들에 대한 기본 인용수가 높다
- 감성분석, MRC, Summarization 등 태스크를 가리지 않고, EMNLP, AAAI, ACL 등에 논문을 엄청 많이 냄.. 그냥 고수
- 이 논문은 NeurIPS 2019
- 191219 기준으로 인용수 26회
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
느낀점
- NLG에서 SOTA를 꽤 찍었는데 방식이 좀 신기
- shared param (같은 모델)로 NLU와 NLG를 할 수 있다는게 가장 큰 장점
- masking으로 장난치면서(?) 모델을 발전시킨건 어쩌면 자연스러운 수순인듯
- 1st segment에서 passage와 answer를 concat하거나 conversation history를 concat 방식으로 집어넣는데, 잘되는게 좀 신기하긴함
- T5가 살아남을지 이 친구가 더 개량되서 살아남을지 궁금
- seq2seq LM을 fine-tuning하는 방법이 좀 신선했음 당연히 left-to-right 방식으로 teacher forcing할줄 알았는데.. ㅎㅎ
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”} {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”} {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}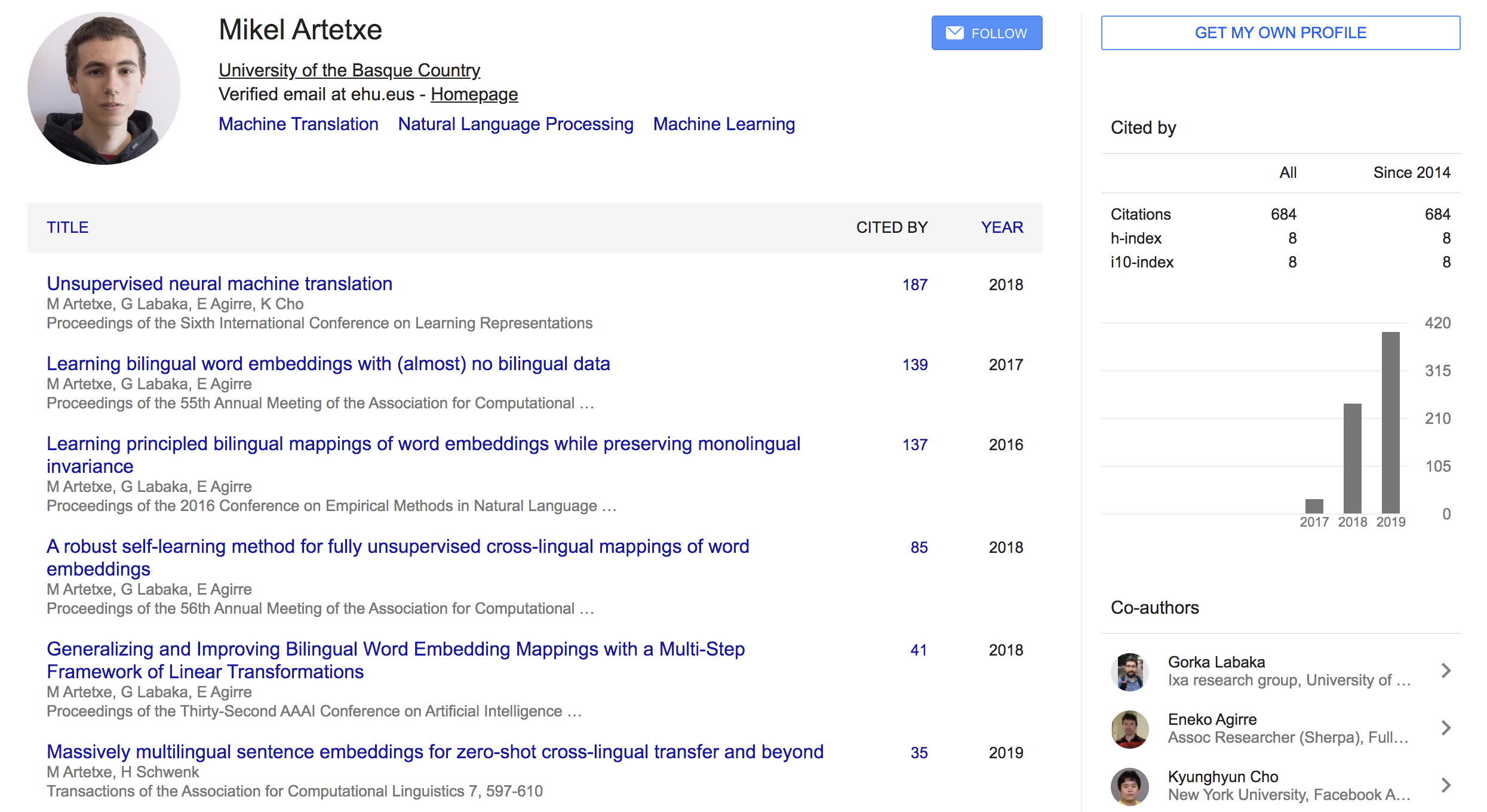 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}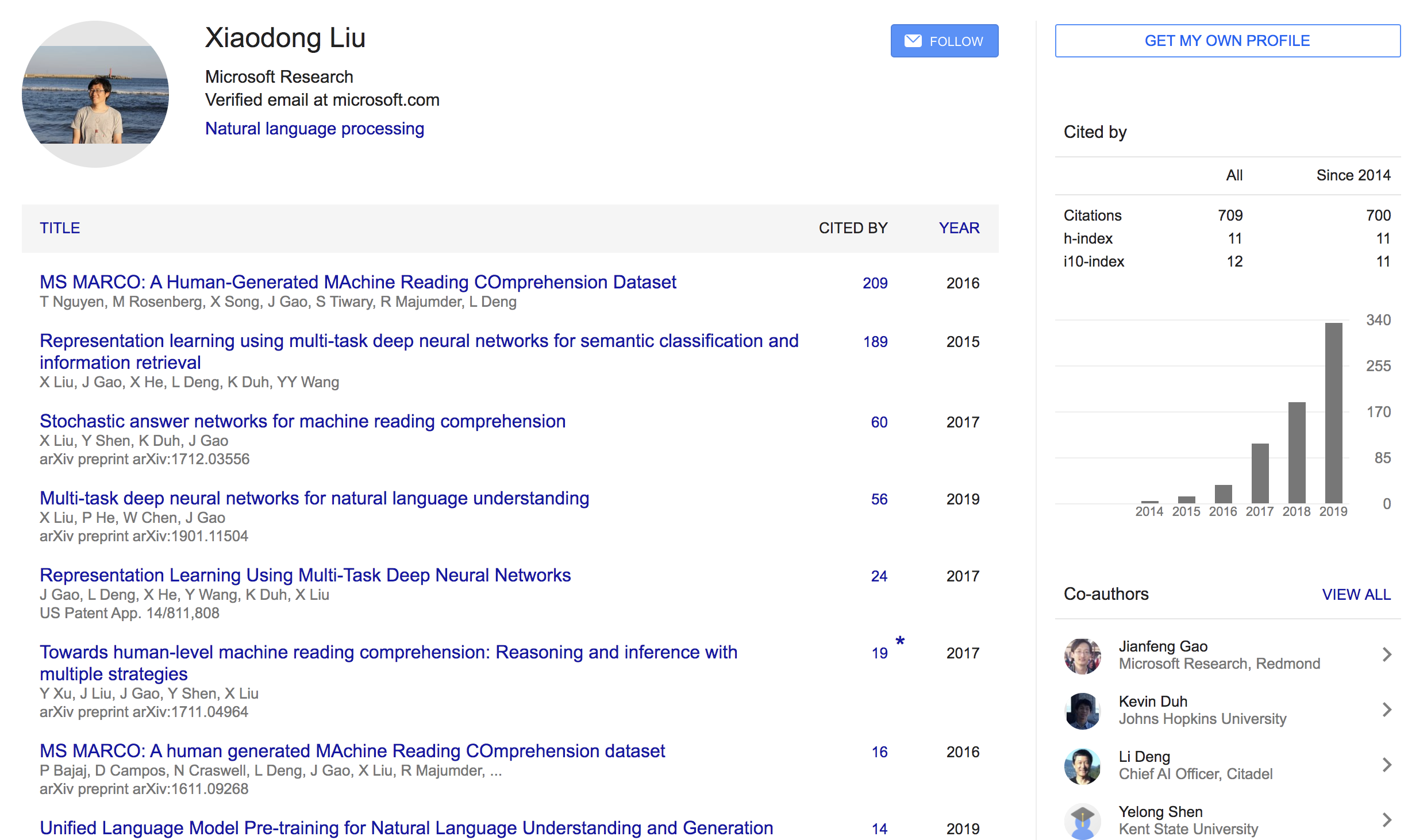 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}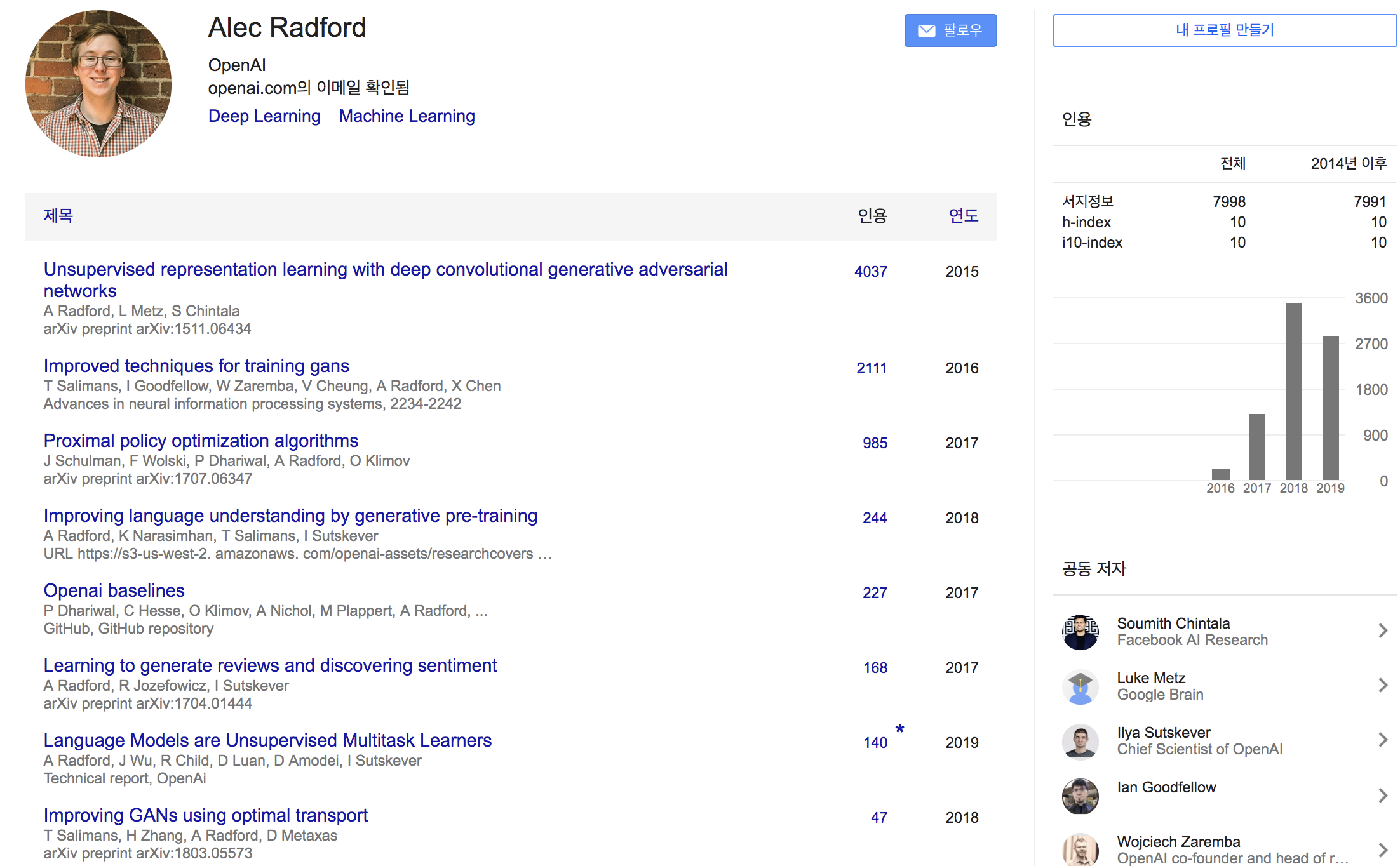 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}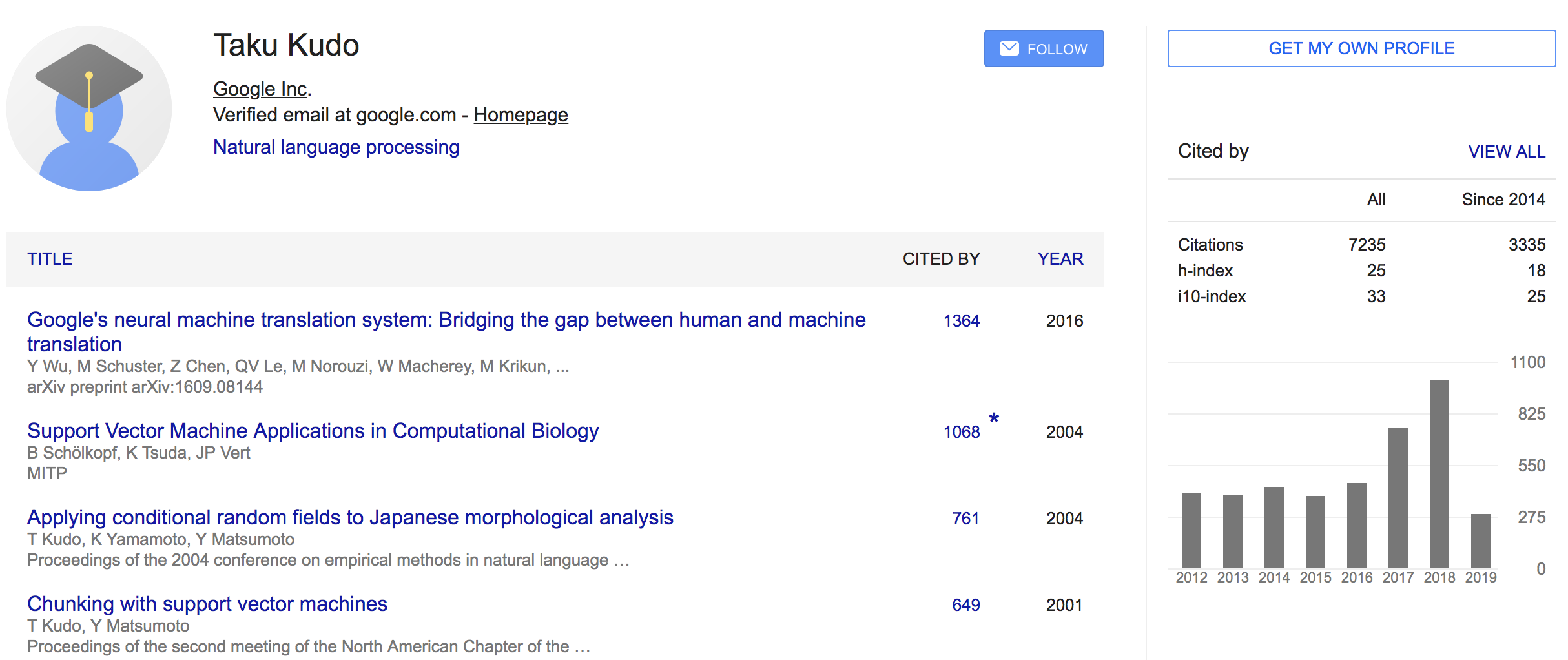 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”} {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}