Attention Is All You Need
이번엔 오늘날의 NLP계의 표준이 된 Transformer를 제안한 논문인 Attenion Is All You Need에 대해서 리뷰해보고자 한다. 대략적인 내용은 이미 알고 있었지만, 디테일한 부분도 살펴보고자 한다.
Author
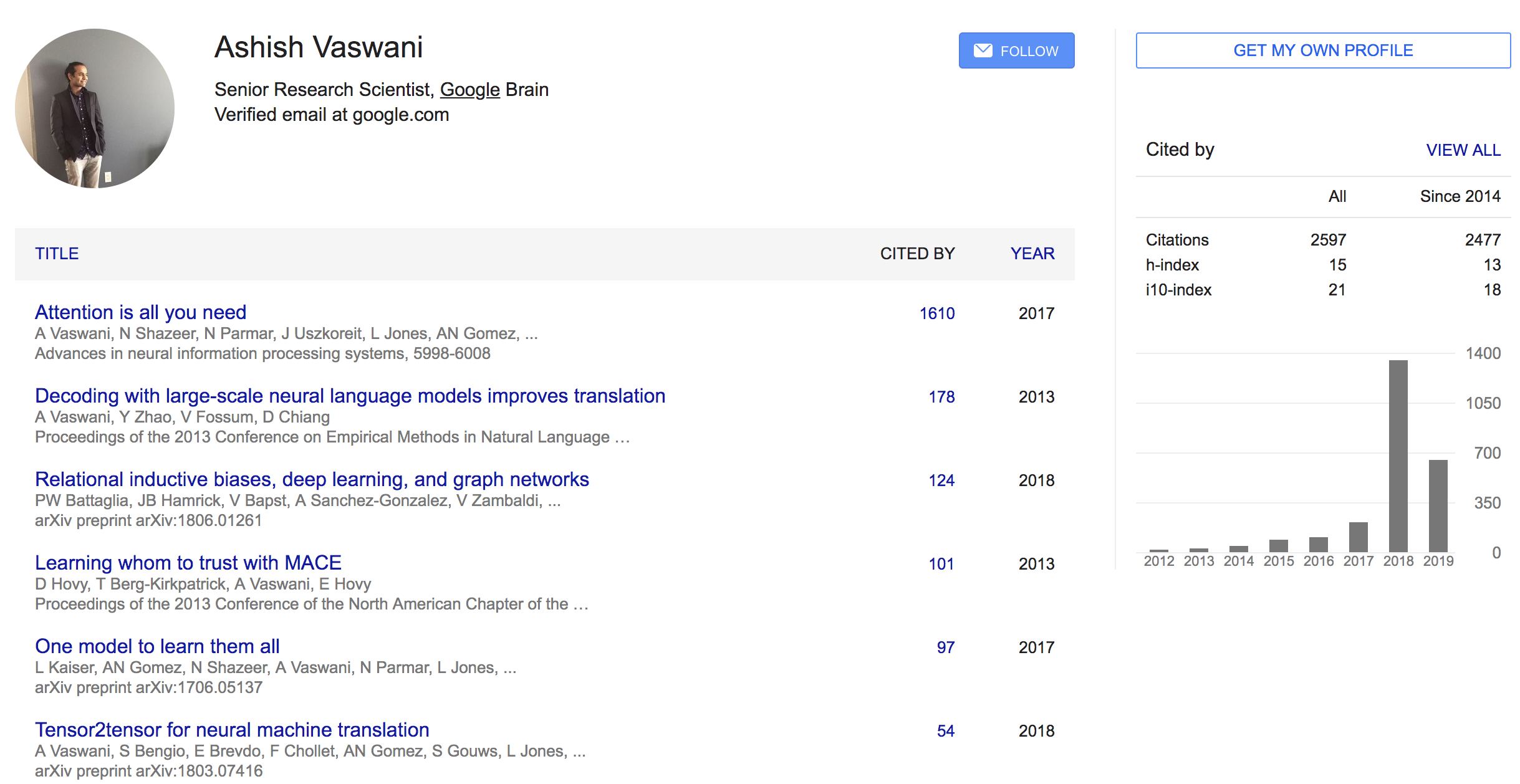
- 저자: Ashish Vaswani, 외 7명 (Google Brain)
구글브레인..wow- NIPS 2017 accepted
Who is an Author?
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
느낀점
- Multi-Head-Attention을 빠르게 구현하기 위해 Matrix 연산으로 처리하되, Embedding Tensor를 쪼갠 후 합치는게 아닌 reshape & transpose operator로 shape을 변경 후 한꺼번에 행렬곱으로 계산해서 다시 reshape 함으로써 병렬처리가 가능하게끔 구현하는게 인상적이었음
- 행렬곱할 때 weight 와 곱하는건 weight variable 생성 후 MatMul 하는게 아니라 그냥 다 Dense로 처리하는게 구현 팁이구나 느꼈음
- 요약: 쪼갠다음에 weight 선언 후 매트릭스 곱? No! -> 쪼갠 다음에 Dense! -> 쪼개면 for loop 때문에 병렬처리 안되잖아! -> 다 계산후에 쪼개자!
- Attention만 구현하면 얼추 끝날 줄 알았는데 Masking 지분이 70~80%였음
- Masking은 logical 연산 (boolean)으로 padding 체크해서 하는게 일반적임
- Masking은 input에도 해주고 loss에도 해줌
- 마스킹 적용할땐 broadcasting 기법을 써서 하는게 일반적임
- 아래의 두 경우 모두 가능함
- ex) (40, 5, 10, 10) + (40, 1, 1, 10) == (batch, head, seq, seq)
- ex) (40, 5, 10, 10) + (40, 1, 10, 10) == (batch, head, seq, seq)
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”} {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}