Author
- 저자:
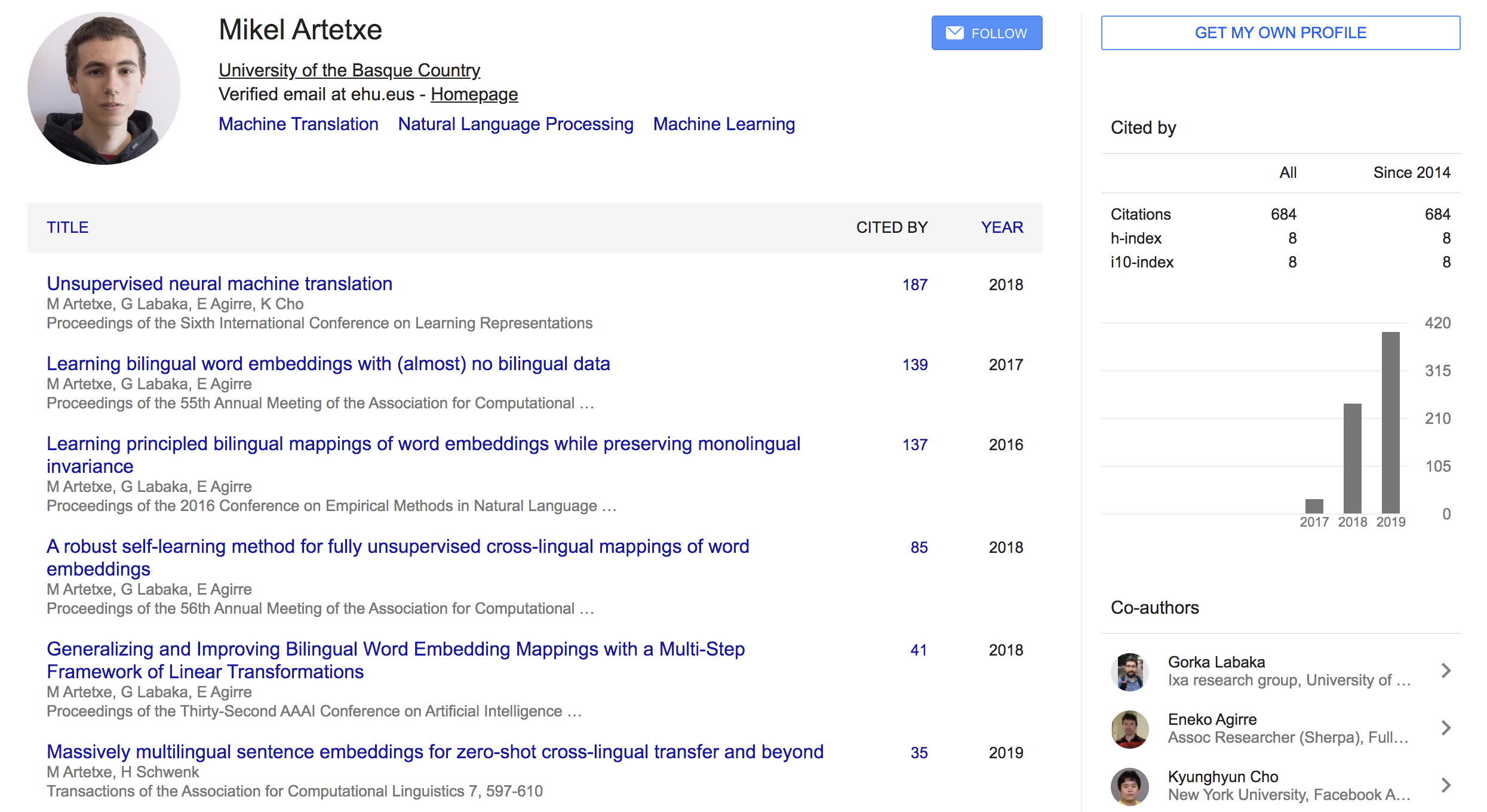
- Mikel Artetxe (University of the Basque Country (UPV/EHU))
- Holger Schwenk (Facebook AI Research)
Who is an Author?
Mikel Artetxe 라는 친구인데 주로 번역쪽 태스크를 많이 한 것 같고 조경현 교수님하고도 co-author 이력이 있음. 페북에서 인턴할때 쓴 논문임.
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
느낀점
- 결국 이 논문도 parallel corpus가 필요하다고함. 이걸 통해 multilingual sentence embedding을 얻는 것임
- Translation이 되게 학습시켜서 encoder를 훈련함
- 대신에 그 양이 좀 적어도 다양한 언어에 대해서 얻을 수 있게 하는 것
- 영어로만 transfer learning 시켰는데도 다른언어도 적용된다는 점은 의미있음
- encoder가 BPE를 통해 language independent하게 모델링했다는게 좀 의미가 있긴한데 한편으로는 universal한 구조다보니 좀 개별언어에 대해서 성능이 최적화되진 않겠다는 생각(
이지만 논문에선 결과가 괜찮음)
- language ID로 decoder에 언어정보를 주는건 꽤 괜찮은 아이디어였다고 생각
- parallel corpus alignment하는거 어떻게하니.. 고생이 눈에 훤함 (꼭 다할 필요가 없다고 했지만서도)
- 이번 논문은 약간 Scaling 으로 승부한 케이스인것 같음 (제목 자체가 그렇지만)
- Scaling을 키워서 실험할 줄 아는것도 결국 연구자의 역량..이라면 인프라가 중요하고 인프라가 중요하다면 configuration 잘하는건 기본이고,
실험비가 많거나 회사가 좋아야(?) 너무 스케일 싸움으로 가는것 같은 논문을 보면 왠지 모르게 아쉽고 씁쓸하다(?)
- 보통 transfer랑 one-shot, few-shot 등의 용어가 나오는데 fine-tune 안한다고해서 zero-shot이라고 한듯
Language-Agnostic 라는 용어: 언어에 구애받지 않는다라는 뜻- BERT 등 최신 논문과도 비교했지만(
1년이 지났으니 최신이라고 이제 할수있을지..) 본 논문의 기법 자체는 좀 옛날 기법이라는 생각이 듬
논문의 설명이 잘나와있으나 몇가지 좀 생략되어있음 (은근 불친절한)
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”} {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}  {: height=”30%” width=”30%”}
{: height=”30%” width=”30%”} {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”} {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”} {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”} {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”} {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”} {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}