Linux, Unix 정리
리눅스 명령어 정리 및 stanford CS1U 강의 요약
자세히 보기 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}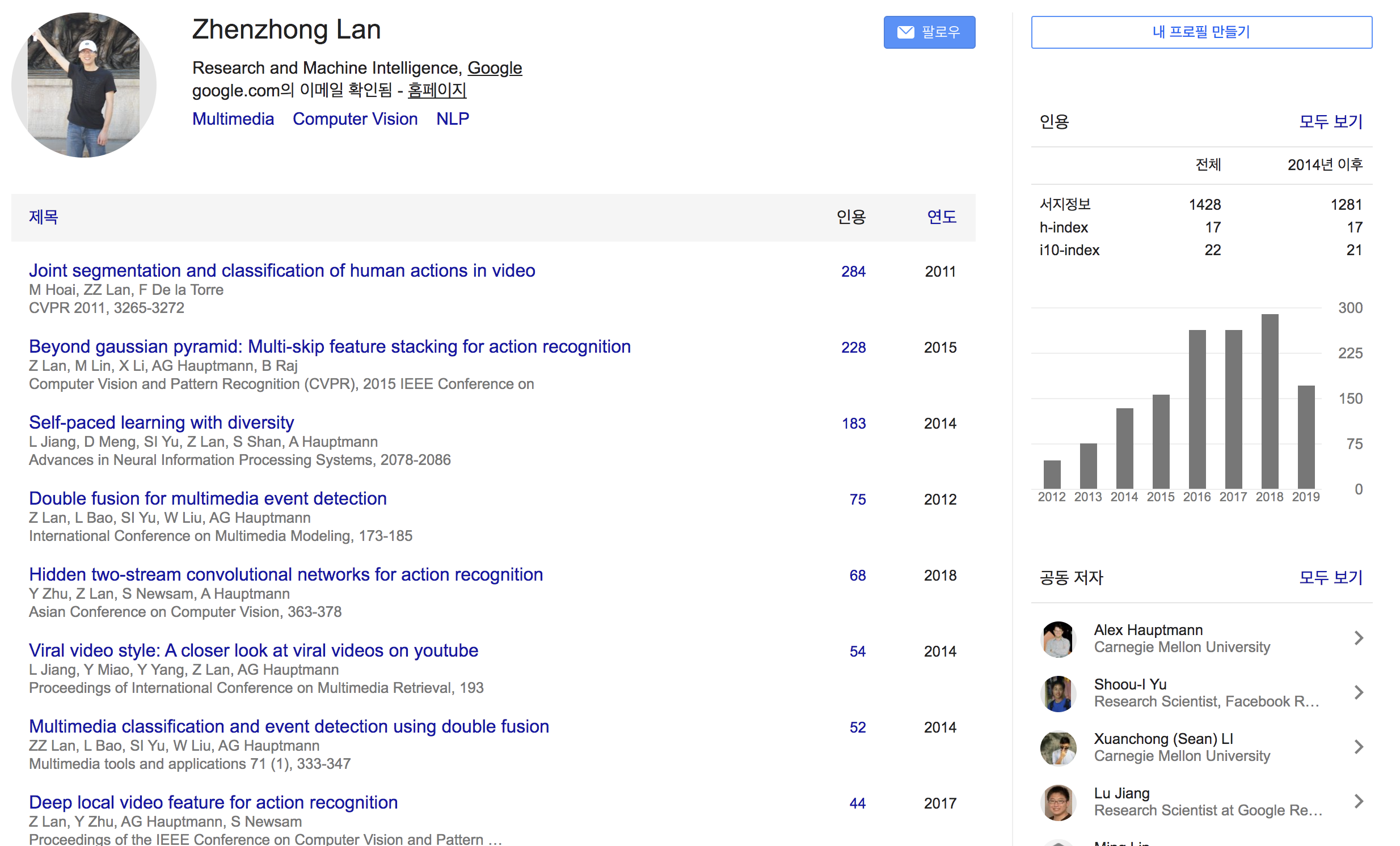 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}Mikel Artetxe 라는 친구인데 주로 번역쪽 태스크를 많이 한 것 같고 조경현 교수님하고도 co-author 이력이 있음. 페북에서 인턴할때 쓴 논문임.
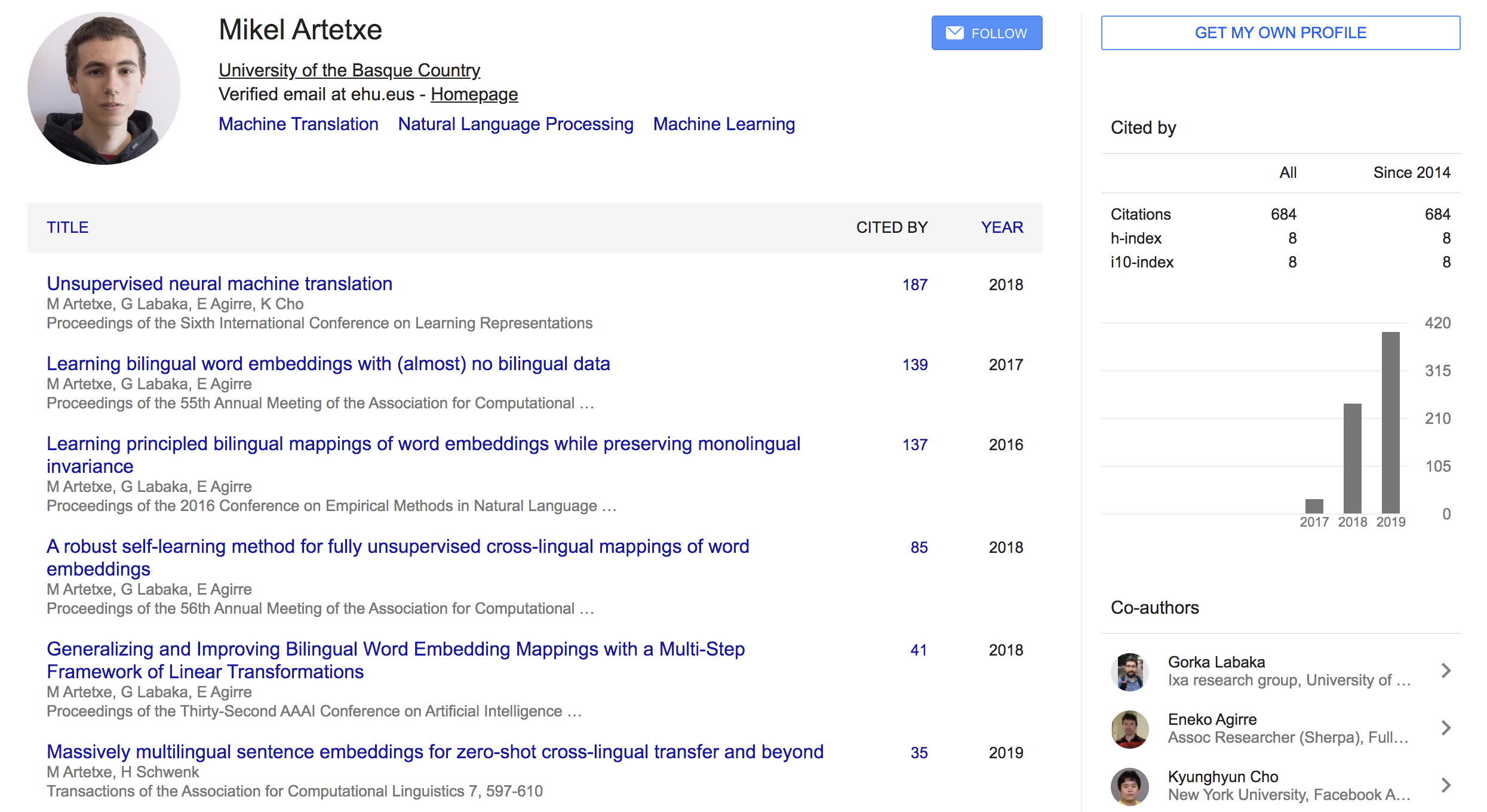 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
Language-Agnostic 라는 용어: 언어에 구애받지 않는다라는 뜻Xiaodong Liu 라는 친구인데 꽤 꾸준히 연구활동을 하는 친구인것 같다.
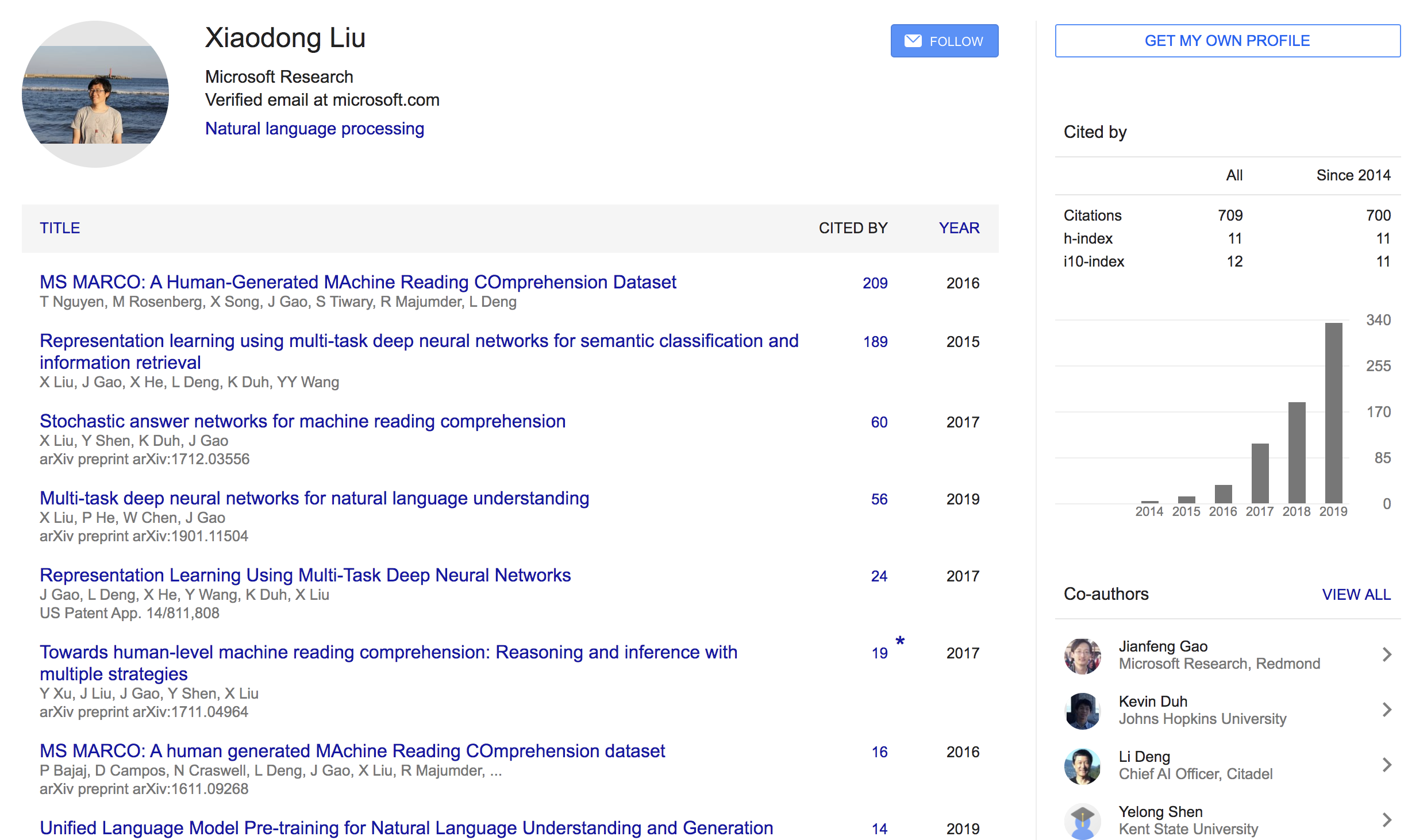 {: height=”50%” width=”50%”}
{: height=”50%” width=”50%”}
사전 확률(prior probability):
사후 확률(Posterior):
MLE(Maximum Likelihood Estimation) 방법
MAP(Maximum A Posteriori) 방법
즉 MLE는 남자인지 여자인지를 미리 정해놓고 시작해서 비교하는거고 MAP는 남자인지 여자인지를 모르는 상태에서 그것이 정해지는 확률까지도 고려해서 비교하는 것임
MAP가 그래서 특정 경우가 정해지는 것에 대한 사전확률을 고려한다고 하는 것임